从“通用能力”到“性能瓶颈”
在现有体系中,FUSE(用户态文件系统)因其通用性与灵活性,被广泛应用于各类云与AI场景。但随着AI负载规模不断提升,其架构限制逐渐显现:
单通道机制带来的资源竞争问题 并发能力受限,难以充分利用多核资源 高负载场景下延迟与吞吐表现受影响
在小文件密集访问等典型AI训练场景中,这些问题会被进一步放大,导致GPU等待数据的情况出现。
产学研协同:从问题定位到架构优化
针对FUSE性能瓶颈,优刻得联合上海科技大学开展专项研究,分阶段推进底层优化工作,双方聚焦FUSE性能瓶颈痛点,联合立项两大研究课题,目前项目均已顺利结题,落地形成实质性技术成果。

阶段一:性能剖析
对FUSE元数据I/O处理链路进行分段分析,定位影响时延与扩展性的关键路径,并交付基于bpftrace的性能分析工具,为后续优化提供数据支撑。
阶段二:性能优化
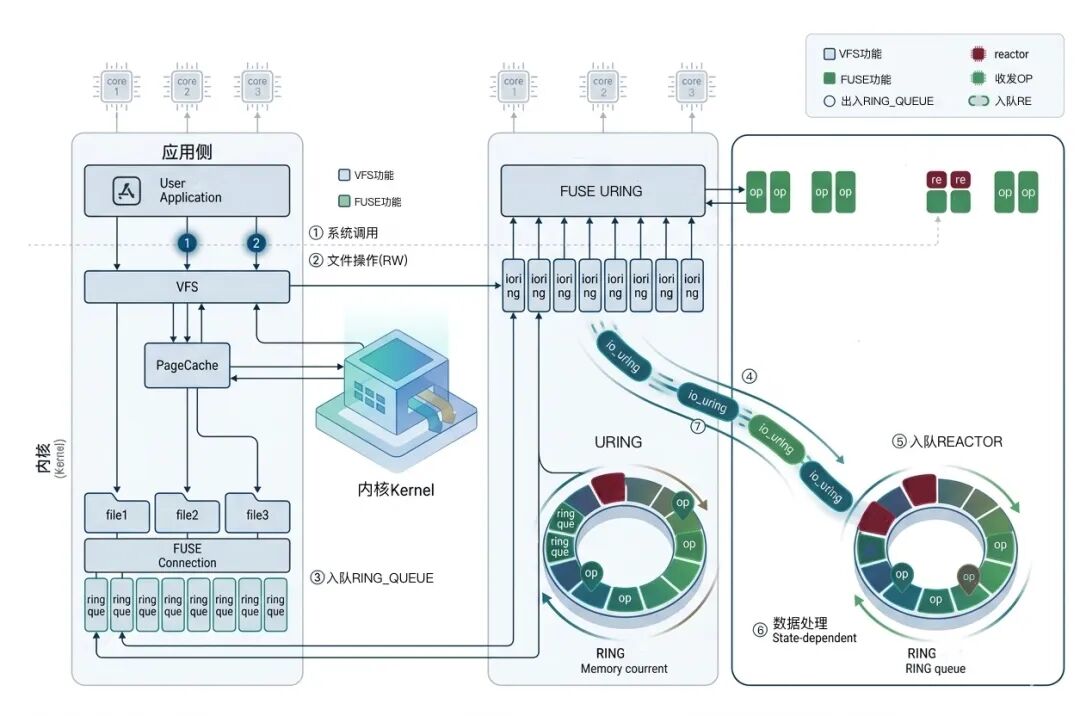
在系统分析基础上,结合业界多种优化思路(如Fuse over io_uring等),设计并实现多队列并行、批处理机制、零拷贝与用户态直通等优化方案,形成可工程化落地的整体架构。
核心升级:构建面向AI的高效数据通路
基于上述研究成果,UPFS完成对FUSE访问路径的重构,引入io_uring机制,实现关键能力:
多核并行处理:为不同CPU核心建立独立处理队列,减少资源竞争,提升整体并发能力。
更高效的数据传输路径:通过优化系统调用与数据传递方式,降低上下文切换开销,并支持零拷贝能力,使数据传输更加直接高效。
在实际测试中,UPFS升级版本相较传统FUSE模式取得明显提升:
4K小IO性能提升3倍以上 大IO吞吐提升约170% 不同IO规模下均表现出更稳定的带宽能力
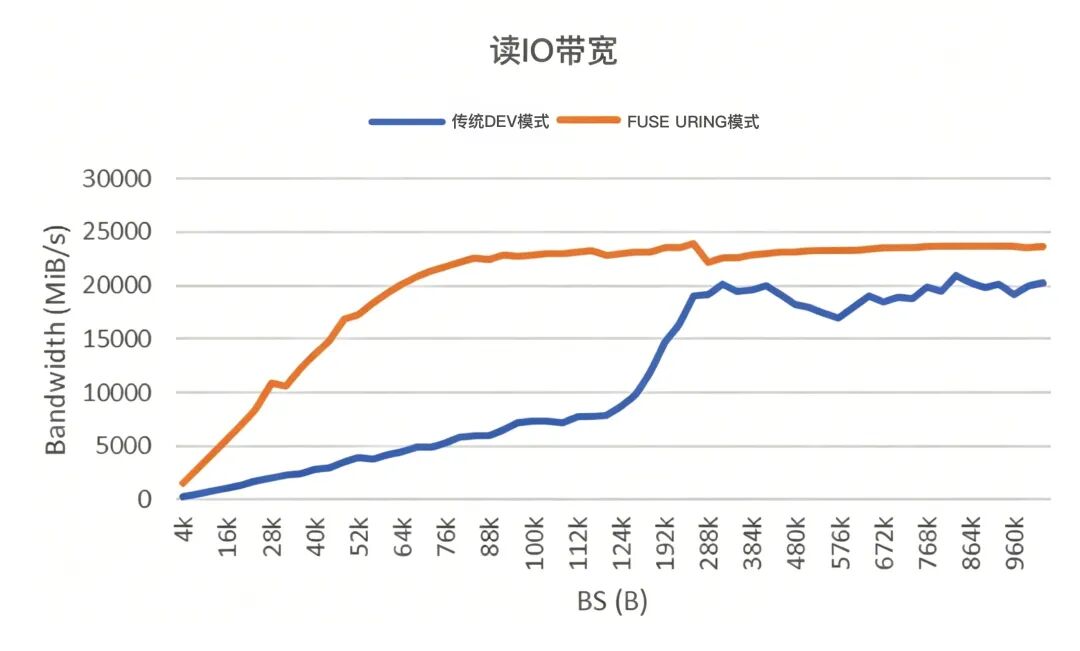
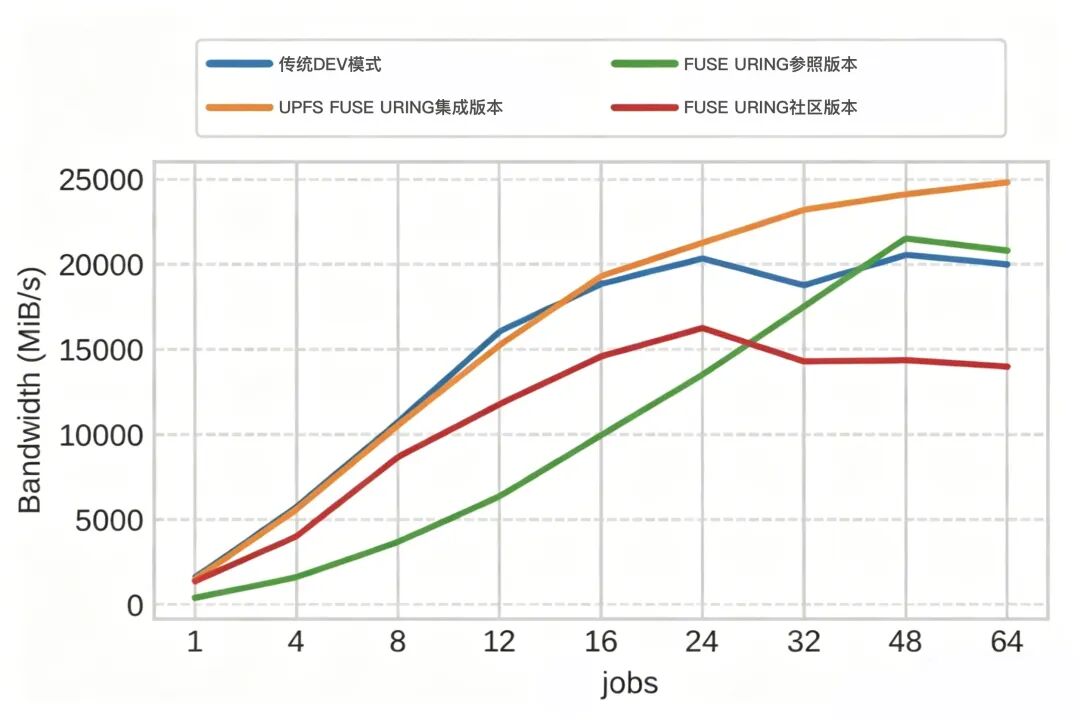
性能提升的直接结果是——GPU等待时间显著降低,整体算力利用率得到有效提升。
面向AI场景的存储能力升级
UPFS的此次升级,不仅是单点性能优化,更是面向AI场景的数据基础设施能力提升:
全场景覆盖:无论是公有云、私有云还是混合云,架构统一 算力协同优化:专为AI算力定制,支持RDMA直通,确保数据高速流入GPU 信创兼容:支持主流国产芯片与操作系统,助力企业构建自主可控的AI底座
通过对存储访问路径的持续优化,UPFS正在帮助企业减少“数据等待”,释放算力价值。优刻得将持续推进AI原生存储技术演进,进一步提升数据与算力的协同效率,为高性能计算场景提供更加稳定、高效的基础设施支撑。
这一技术突破的背后,不仅是优刻得在高性能存储领域的持续深耕,更体现了校企协同创新的独特价值。通过与上海科技大学的深度合作,双方实现了从理论研究到工程落地的高效转化,加速前沿技术在产业场景中的实际应用。

 沪公网安备 31011502006855号
沪公网安备 31011502006855号