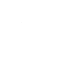上海科技大学信息科学与技术学院任侃课题组致力于探索机器学习方法与基础模型创新及其在数据科学领域的应用,包括时空数据挖掘与数据科学人工智能体(AI Agents)、语言视觉基础模型机制发现与可解释等方向。近日,课题组与微软研究院合作,在基于大语言模型的数据科学自动化、语言智能体、数据可视化等方面取得多项研究成果。
VisEval:一种新颖的“自然语言到可视化”基准,用于对生成的可视化进行全面且可靠的评估
将自然语言转化为可视化在数据分析领域具有巨大的潜力,但也面临诸多挑战,如准确解释自然语言查询、选择适当的可视化方式,等等。大语言模型的出现为这一任务开辟了新的路径,然而这个新的方向缺乏全面可靠的基准,这阻碍了对基于自然语言的可视化方法的进一步理解与性能提升。
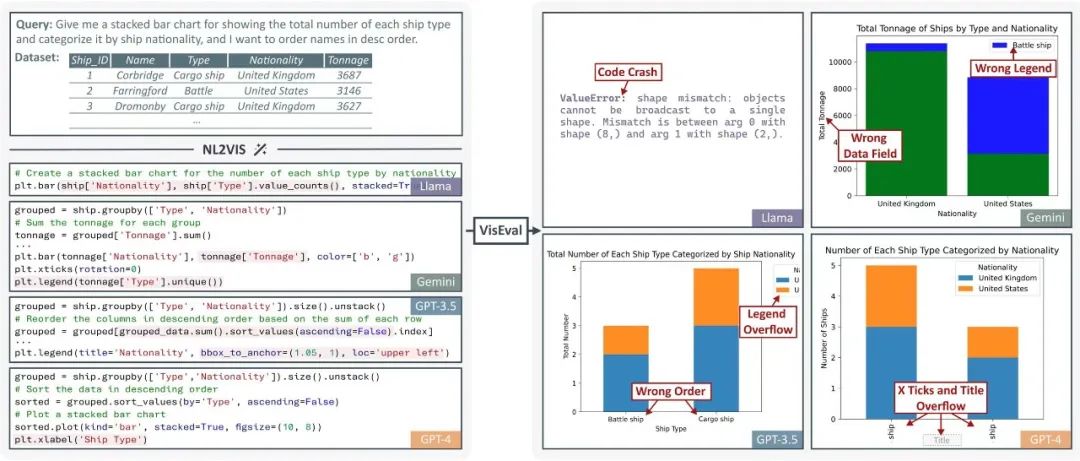
图1.1 基于大语言模型的自然语言到可视化流程及其存在的问题
为此,课题组提出了 VisEval 来解决这一问题。首先,作者建立了一个大规模的数据集,涵盖了来自146个数据库的2524个具有代表性的自然语言查询。通过结合大语言模型和可视化专家的经验对数据进行过滤,以确保数据集的高质量。随后,作者建立了一个新颖且可靠的自动化评估框架,涵盖了有效性、合法性、可读性等多个维度。VisEval从不同角度对当前最先进的大语言模型进行了全面评估,揭示了其能力与局限性,并探讨了基于自然语言的可视化分析的未来发展方向。

图1.2 VisEval的流程包括三个关键模块:有效性检查器、合法性检查器和可读性评估器
该研究成果由上海科技大学信息科学与技术学院任侃课题组与微软亚洲研究院联合完成,并以“VisEval: A Benchmark for Data Visualization in the Era of Large Language Models”为题发表在 IEEE Visualization Conference (VIS 2024)。VIS会议是数据可视化和可视分析领域的国际学术会议,属于中国计算机学会推荐CCF-A类会议。文章获得会议最佳论文奖(Best Paper Award),任侃教授为共同通讯作者。
文章链接
https://arxiv.org/pdf/2407.00981
DSEval:一种新颖的数据科学智能体评估范式
数据科学通过分析大量数据来支持决策。然而,数据驱动的决策过程需要掌握复杂的分析工具和专业知识,这个过程即使对专家来说也是一大挑战。将大语言模型作为数据科学智能体是一种有用的辅助方式,这些智能体能够在特定的平台上执行各种以数据为中心的任务,帮助人类进行数据分析和处理。然而,由于数据科学的复杂性,这些智能体的能力受到限制。正确评估数据科学智能体对于查明其能力和局限性并提升其性能至关重要。
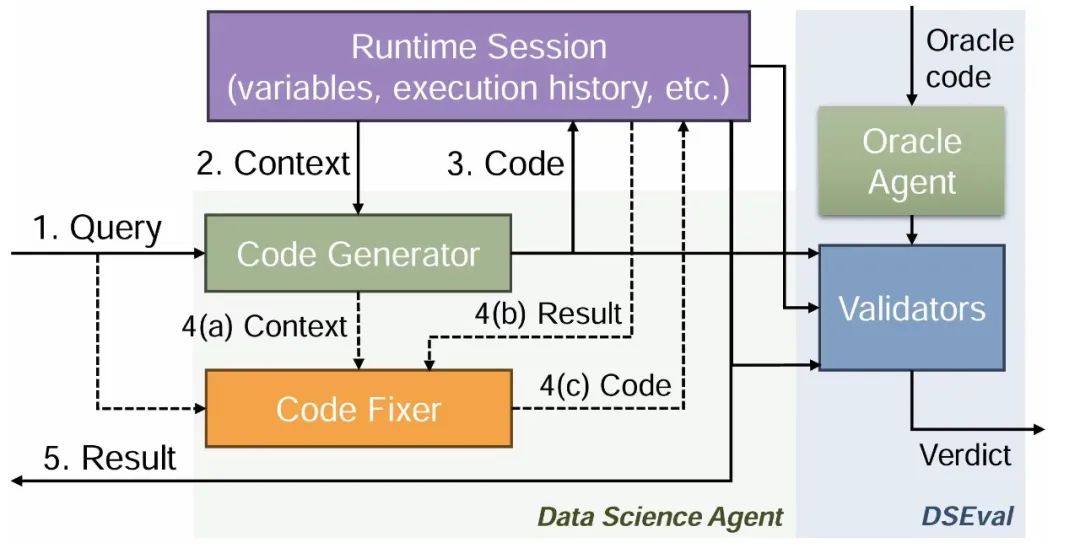
图2.1 数据科学智能体完整的任务周期由 DSEval 所监控与评估
课题组提出了一种新颖的评估范式DSEval,以及一系列为评估数据科学智能体定制的基准。DSEval 将数据科学智能体的评价范围扩大到整个智能体任务的生命周期,并评估其整体行为与细节。
图2.2 大语言模型引导注释过程
为确保基准测试的覆盖面,课题组还提出了一种新颖的引导注释流程DSEAL,这是一种人类与大语言模型均可理解与处理的流程范式,继而利用大语言模型自动生成问题集,并结合少量的人工输入与评估。基于DSEval,作者构建出四个基准测试,包含不同属性、不同难度及覆盖不同数据科学处理工具库的问题集,显著提高了基准测试的可拓展性和覆盖范围。
该研究成果由上海科技大学信息科学与技术学院任侃课题组与微软亚洲研究院联合完成,并以“Benchmarking Data Science Agents”为题发表在第六十二届计算语言学协会年度会议Annual Meeting of the Association for Computational Linguistics(ACL 2024)主会,ACL是自然语言处理领域的国际学术会议,属于中国计算机学会推荐CCF-A类会议。上海科技大学本科生江其洋、韩星宇为论文第二、三作者,任侃教授为通讯作者。
文章链接
https://arxiv.org/pdf/2402.17168
MLCopilot:首个基于大语言模型的自动机器学习框架
近年来,机器学习已得到广泛应用,但在特定任务中,配置并执行相应的机器学习解决方案并非易事,这是由于机器学习算法的解空间非常庞大且这些算法对任务上下文中微小变化非常敏感。而现有的自动化机制不仅耗时且难以理解,这些方案通常只适用于特定领域,迁移能力仍然存在挑战。
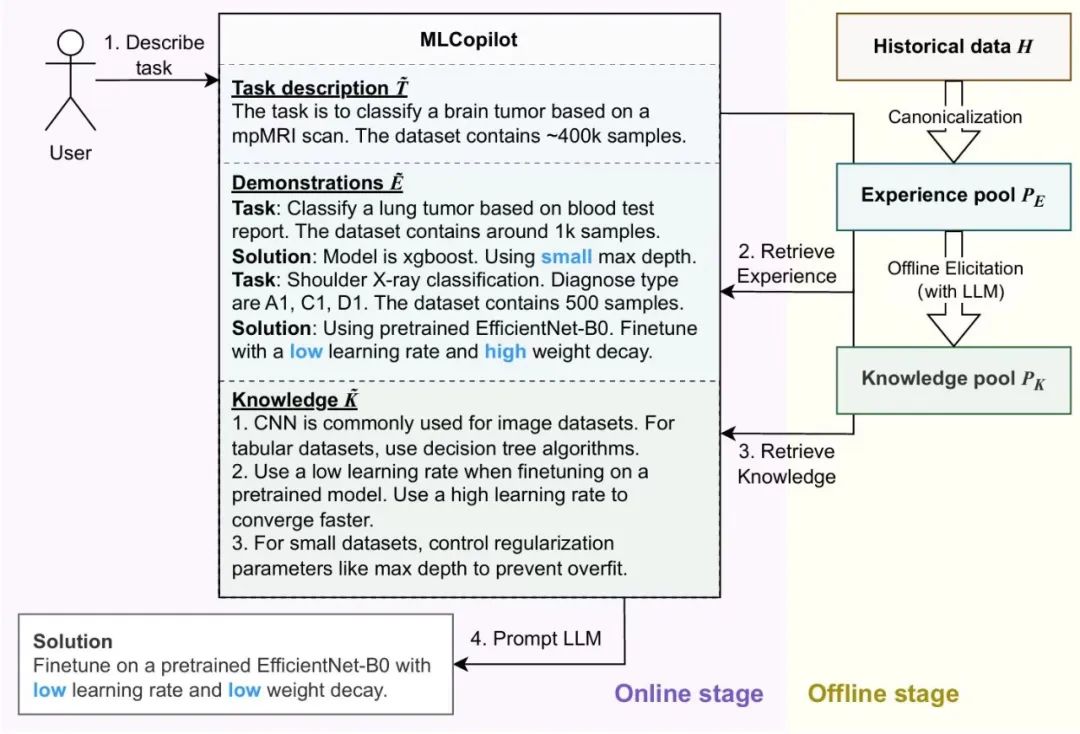
图3.1 MLCopilot 框架图。MLCopilot 分为离线阶段和在线阶段
为了解决这些问题,课题组提出了首个基于大语言模型的自动机器学习框架MLCopilot ,基于现有机器学习任务的经验进行观察和推理,帮助人类在全新的数据科学任务中分析数据、绘制图表,甚至自动构建机器学习解决方案。
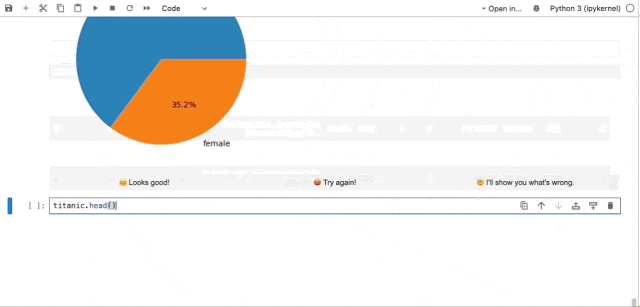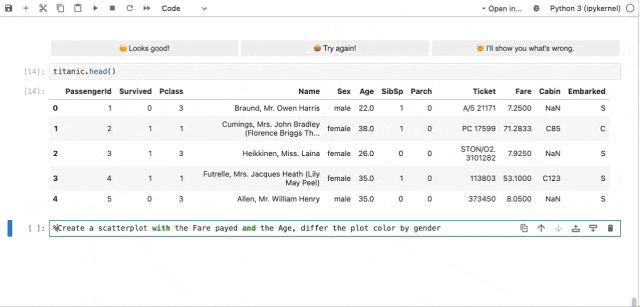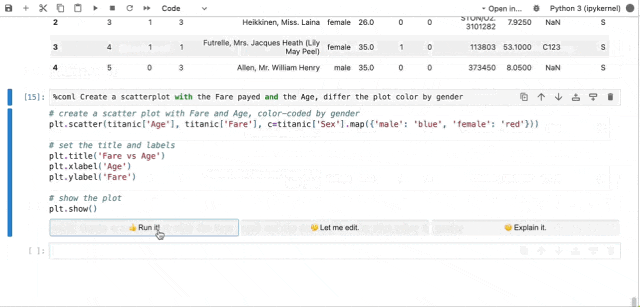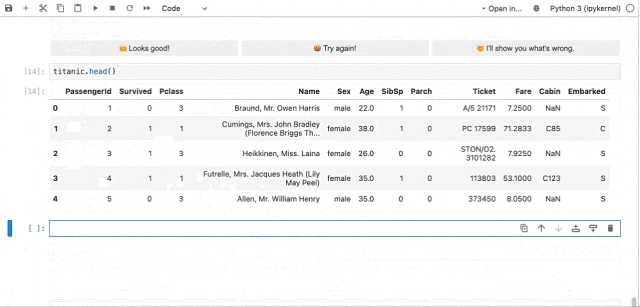
图3.2(动图) MLCopilot自动数据分析示例
MLCopilot 将流程分为离线和在线两个阶段。在离线阶段,MLCopilot对机器学习模型的历史训练与测试数据进行规范化并创建经验池,大语言模型从这些历史经验中获取知识。在在线阶段,MLCopilot 根据目标任务的描述,从经验池中检索最相关的任务的经验,并与大语言模型交互以生成合适的机器学习解决方案。通过这种设计,MLCopilot 结合机器智能和人类设计模式,为机器学习任务生成可解释的结果。
该研究成果由上海科技大学信息科学与技术学院任侃课题组与微软亚洲研究院联合完成,并以“MLCopilot: Unleashing the Power of Large Language Models in Solving Machine Learning Tasks”为题发表在自然语言处理领域国际知名会议European Chapter of the Association for Computational Linguistics (EACL 2024),并获得杰出论文奖(Outstanding Paper Award),任侃教授为通讯作者。
文章链接
https://arxiv.org/pdf/2304.14979

 沪公网安备 31011502006855号
沪公网安备 31011502006855号