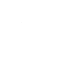信息学院视觉与数据智能中心何旭明课题组专注于视觉感知、自然语言和生物信息等多模态复杂数据的表征学习和推理,并探索小样本和多任务下的弱监督学习和模型泛化。近期,该课题组在“IEEE计算机视觉与模式识别会议” (IEEE Conference on Computer Vision and Pattern Recognition,CVPR 2021)上发表了四篇文章,展现了他们今年在相关研究领域所取得的最新进展。
面向无偏场景图生成的自适应消息传递机制二分图神经网络
场景图生成是一项重要的视觉理解任务,具有广泛的视觉应用。作为一种结构化的高阶视觉信息,通过将物体和物体之间的交互关系表示为三元组的形式(主体,交互关系,客体),将实体链接起来,构成图的形式来对场景进行表征。这样一个表征能够有效的为如视觉问答、视觉检索等下游任务提供一个可靠的基础。
尽管学术界在相关领域已经取得很多进展,但由于视觉关系的类别空间具有本质性的长尾分布和高度多样化的类内变化特征,识别视觉关系仍然具有挑战性。为了解决这些问题,研究人员提出了一种新的具有自适应消息传播机制的置信感知二分图神经网络,通过对场景图上下文语意依赖的稀疏性进行更为灵活有效的建模,从而进一步的改善了目前模型在无偏场景图生成上的问题。此外,我们还提出了一种针对实体识别任务的双层数据重采样策略,相比于已有的各种重采样方法,有效地缓解图网络训练中数据分布不均衡情况,在对高低频类别的识别性能上取得了更优的平衡。
该方法在Visual Genome、Openimage V4/V6等具有挑战性的大规模开放数据集上取得了优于以往方法的性能,证明了该方法的有效性和通用性。
该论文题为Bipartite Graph Network with Adaptive Message Passing for Unbiased Scene Graph Generation; Rongjie Li, Songyang Zhang, Bo Wan, Xuming He。此项工作的主要完成单位为上海科技大学,其中信息学院2019级研究生李荣颉为第一作者,2019级博士生张松阳、2017级研究生、现鲁汶大学博士生万博为第二,第三作者,何旭明为通讯作者。该研究得到上海市自然科学基金以及上海科技大学信息学院启动基金支持。
文章链接 https://arxiv.org/abs/2104.00308
图|左子图展示了该工作提出的算法流程和模型模块,右子图为该工作提出的自适应消息传播机制的置信感知二分图神经网络的示意图。
一种基于关系感知以及实例修正的弱监督视觉定位模型
随着人工智能的快速发展,多模态的交互理解变得愈发重要。其中很重要的一环就是建立视觉实例以及短语之间的匹配关系。这是众多多模态交互理解的基础部分。其中视觉问答、视觉导航、视觉对话都需要此项技术作为基础模块。当前的方法是从一堆固定的、实现计算好候选框中选出与短语最匹配的视觉实例。该类方法往往导致较差的物体定位以及歧义匹配。在该文章中,作者提出了一种结合上下文语义关系建模的弱监督学习方法。该方法结合了由粗到细的筛选策略以及实例关系建模,能够产生更加准确的视觉定位结果。研究人员为了更加有效的训练整个网络,又提出了一个自我教学的回归损失函数,以及关系分类损失函数。这些函数能够使得网络在缺少监督信号的情况下不断地优化候选物体位置坐标,以及显式地建模上下文关系。该方法在现有的Flickr30k Entities以及ReferItGame 数据集上大幅度超越现有方法性能,取得领先地位。
该论文题为Relation-aware Instance Refinement for Weakly Supervised Visual Grounding。此项工作由上海科技大学、鲁汶大学、美团等单位协作完成,上海科技大学信息学院2019级博士生刘永飞,2017级研究生、现鲁汶大学博士生万博共同完成。美团首席科学家马林提供讨论。何旭明为通讯作者。该研究得到上海市自然科学基金以及上海科技大学信息学院启动基金支持。
文章链接:https://arxiv.org/pdf/2103.12989.pdf
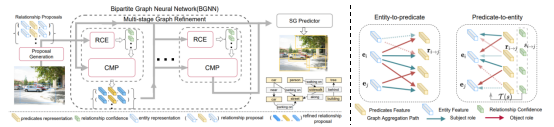
图|模型概览图。该模型主要由4个部分构成,分别是骨干网络,粗粒度匹配网络,视觉关系图网络,细粒度匹配网络。骨干网络主要用来提取视觉特征以及短语特征;粗粒度匹配网络主要用来选择一小部分与短语相关的候选框。视觉关系图网路主要是用来建模视觉中的上下文关系;最后细粒度匹配网络主要是得到最终的匹配结果。
分布对齐:一个面向多种长尾视觉识别任务的统一框架
长尾数据分布在多种多样的计算机视觉任务中普遍存在。如何提升长尾数据分布下各类任务的性能,是学术界和工业界最近一段时间都关注的问题。在长尾数据分布下,各个类别的数据样本出现频率差异巨大。这种长尾特性,往往需要计算机视觉模型能同时处理高频类别、中频类别和低频类别,给视觉任务带来了很大的挑战。
尽管深度学习在计算机视觉任务中取得了巨大成功,但是仍然在长尾问题上性能不佳。在此项研究中,研究人员首先分析了当前常用解决方案的性能瓶颈,提出了一种处理多种视觉任务的通用策略。方案包括一个数据自适应的矫正函数,用来对输入数据的分类低分进行修正。同时提出了一个广义重加权策略,来引入数据集先验。这种方式简单有效,可以直接应用于多种数据任务而无需进行特殊设计。这种统一框架在4个计算机视觉任务的6个数据集上进行了实验验证(图像分类、物体检测、语义分割、实例分割),均取得了优异效果。
该论文题为Distribution Alignment: A Unified Framework for Long-tail Visual Recognition。此项工作由上海科技大学、旷视研究院等单位协作完成,上海科技大学信息学院2019级博士生张松阳为第一作者。旷视研究院黎泽明、孙剑提供讨论。何旭明为通讯作者。该研究得到上海市自然科学基金,上海科技大学信息学院启动基金,国家重点研发计划以及北京智源人工智能研究院的支持。
原文链接:https://arxiv.org/pdf/2103.16370
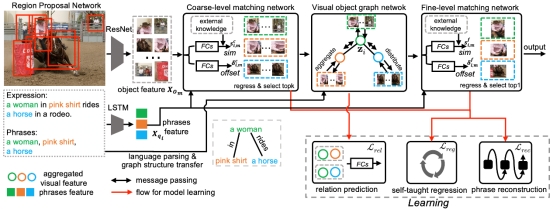
图|长尾数据分类现有方案的性能上限分析
基于动态扩展表示的类增量学习
类别增量学习要求模型能够在不遗忘旧概念的基础上不断理解新概念, 这也是迈向自适应视觉智能的关键一步。具体来说,需要考虑如何在增量学习中仅记忆有限数据点的情况下实现更好的模型稳定性与可塑性的平衡。为了达到这一目的,研究人员提出了一个新颖的基于可动态扩展表示的两阶段学习方向。在三个常用类别增量学习基准包括CIFAR-100, ImageNet-100和ImageNet-1000上,以及有无预训练模型的两种情形下均做了广泛的实验。实验结果显示该方法能够使用相同甚至更少的参数量实现在多个不同的基准上均大幅超过现有的其他方法。除此之外, 研究发现其方法还可以实现一定的有益的正向以及后向的知识迁移。
该文章题为DER: Dynamically Expandable Representation for Class Incremental Learning。此项工作被CVPR 2021接受为口头报告(Oral),由上海科技大学2019级博士生颜世鹏与2018级硕士生谢江炜为共同第一作者,何旭明为通讯作者。该研究得到上海市自然科学基金以及上海科技大学信息学院启动基金支持。
文章链接:https://arxiv.org/abs/2103.16788
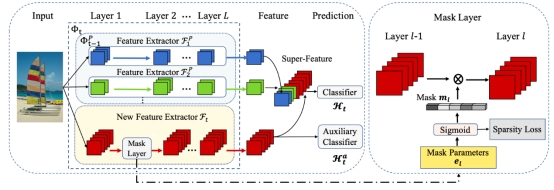
图|动态扩展表示学习。模型由超特征提取器以及分类器组成。在增量学习步骤t, 超特征提取器由通过一个新的特征提取器对已有的超特征提取器进行扩展而来。我们也使用了一个辅助分类器来对模型做正则化。除此之外,通道级掩码与模型表示是联合学习的, 而通道级掩码会在表示学习完后用于对模型结构做精简。
CVPR是IEEE一年一度的国际学术会议,是计算机视觉领域三大代表性学术会议之一, 在国际上享有很高的声誉。根据谷歌学术指标(Google Scholar Metrics)截止至去年6月的统计数据, CVPR在所有被谷歌所收录刊物和会议中综合影响力排名第五。

 沪公网安备 31011502006855号
沪公网安备 31011502006855号