近日,信息学院视觉与数据智能中心多项研究成果在计算机视觉和计算机多媒体领域顶级会议上发布,包括European Conference on Computer Vision(ECCV)2020论文 4篇、ACM International Conference on Multimedia(ACM MM)论文 2篇。ECCV 是计算机视觉领域三大顶级会议(ECCV、ICCV和CVPR)之一,在国际上享有很高的声誉,也是全球计算机视觉前沿研究的风向标。 ACM MM是中国计算机学会推荐A类国际会议。
何旭明课题组提出了一种新颖的基于原型的语义分割小样本学习框架。语义分割是现代计算机视觉中的一项核心任务,在如自动驾驶、医学图像理解等方面都有许多实际运用,但是目前基于深度卷积神经网络的研究方法还是存在很多局限。何旭明课题组以小样本学习策略入手,解决了上述问题的局限性。实验结果表明该方法极大超越了state-of-the art,在Pascal数据集的1-shot和5-shot的设置下分别有3.32%和3.30%的提升,在COCO数据集上分别是7.84%和15.48%的提升。该成果以Part-aware Prototype Network for Few-shot Semantic Segmentation为题发表在ECCV 2020上。何旭明课题组博士生刘永飞、硕士生张相宜是该论文共同第一作者,何旭明教授为通讯作者。
论文原文:https://arxiv.org/abs/2007.06309
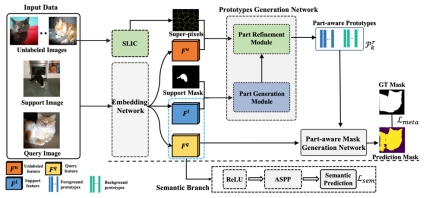
图| 基于局部感知原型的小样本分割网络
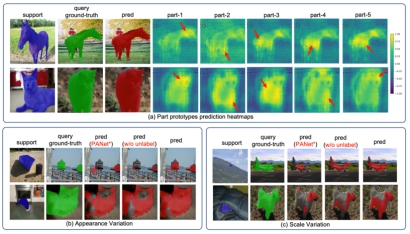
图|(a)局部感知原型热力图 (b)针对颜色变化大的预测结果 (c)针对尺度变化大的预测结果
人工智能在医学图像分析中也有广泛的应用。在医学图像辅助诊断中,传统的方法需要大量有标注的疾病数据训练模型,获取难度较大。为了减少对标注的依赖,高盛华课题组对医学图像中的异常检测问题展开研究。异常检测是指在训练阶段仅利用正常图像训练模型,由此得到一个可以识别正常和异常的分类器。他们观察到来自健康者的医学影像通常具有规则的结构,相反,疾病和损害常常破坏这些结构。因此,课题组挖掘结构和纹理的关系,提出了新的异常检测算法。该研究方法在眼底彩照和OCT图像的异常检测上取得国际领先性能。该成果以Encoding Structure-Texture Relation with P-Net for Anomaly Detection in Retinal Images 为题发表在ECCV 2020上。高盛华课题组2019级博士生周康和2018级硕士生肖宇廷为本文的共同第一作者,高盛华教授为通讯作者。
原文链接:http://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123650358.pdf
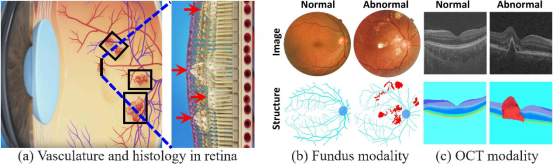
图| 利用结构信息解决异常检测的动机示意图
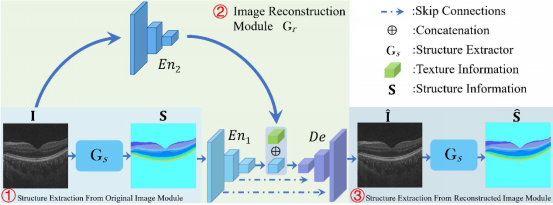
图| 本文提出的模型示意图
高盛华课题还在室内场景中的无监督深度预测方面开展了系列研究。室内场景由于其极多的无纹理区域,会使得许多针对室外场景设计的无监督深度预测的网络在室内场景应用中完全不收敛。为此,课题组在深入分析之后,提出P2Net,一个专门为室内场景设计的无监督深度预测框架,该方法解决了点与点之间匹配不显著的问题。实验结果在多个室内数据集上达到了优秀的性能,甚至可以媲美一些完全有监督的算法。该成果以P2Net: Patch-match and Plane-regularization for Unsupervised Indoor Depth Estimation发表在ECCV会议上。高盛华课题组的学生余泽浩和金磊为共同第一作者。项目获得国家重点研发计划,国家自然科学基金委员会以及上科大-旷世联合实验室的大力支持。
原文链接:https://arxiv.org/pdf/2007.07696.pdf
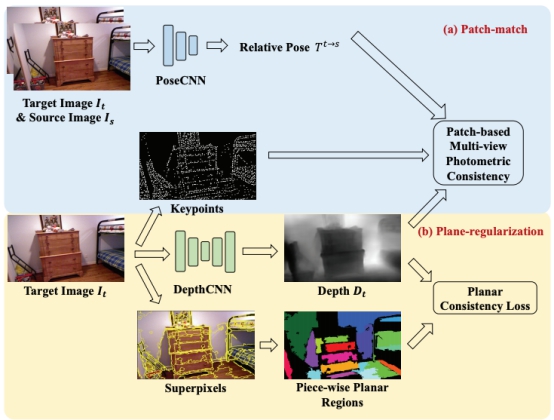
图| 本文中提出的网络结构示意图
许岚课题组与清华大学的LuVion团队方璐教授合作,提出了一种新型的鲁棒人体动态捕捉系统。该系统仅使用单个消费级RGBD传感器,解决了人体数字孪生中,最核心和最关键的高质量、便捷式、完整式人体动态四维重建问题。传统方法在单目采集的限制下,受到固有的自扫描限制(需要人转圈来采集完整模型),并随之导致高度脆弱的人体动态捕捉。为了打破这样的约束,课题组提出了一个数据驱动的模型完整化算法,只使用单张前视图像输入,就能生成完整且精细的初始模型。为了实现稳健的动态捕捉,课题组还进一步采用混合运动优化和语义体积融合的方案,可以在单目设置下成功进行高难度人体动作重建,无需预先扫描人体模板,并拥有从跟踪失败和人体重现等重复场景中恢复的重新初始化能力。
大量实验证明,该方法可以稳健实现高质量的人体高难度动作动态四维重建,打破了繁琐的自扫描限制。该论文以RobustFusion: Human Volumetric Capture with Data-driven Visual Cues using a RGBD Camera 为题发表在ECCV 2020。许岚教授和清华大学苏卓为共同第一作者,清华大学方璐教授为通讯作者。
原文链接:https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/1802_ECCV_2020_paper.php
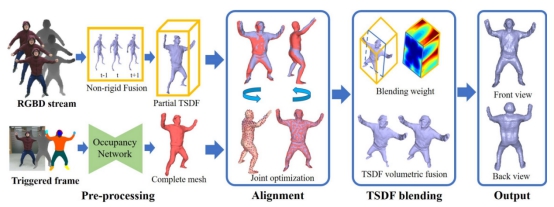
图| 流程图
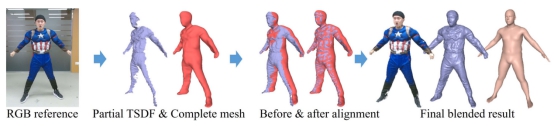
图| 模型完整化的结果

图| 高质量人体动态捕捉结果
虞晶怡课题组有两篇论文被ACM MM 2020会议接收。论文Neural3D: Light-weight Neural Portrait Scanning via Context-aware Correspondence Learning 提出了一种仅使用单个RGB相机的新型神经人像扫描系统,实现了轻量化高真实感人像重建。在该系统中,课题组提出了一种上下文感知的特征点匹配学习方法,用以准确的姿势估计,并进一步联合对特征对之间的纹理、空间和运动信息进行建模。课题组采用了基于点云的神经渲染方案,以便在任意虚拟视点上生成逼真的沉浸式人像可视化,实现了逼真的重建并抑制了几何误差。通过将这些基于学习的技术引入纯基于RGB的人体建模框架中,最终实现了精确的相机姿态估计和逼真的重建人像的自由视点渲染。该成果在各种具有挑战性的捕获场景中进行的大量实验,并进一步验证了方法的稳健性和有效性。研究生索鑫为该论文的第一作者,博士生吴旻烨为第二作者,虞晶怡教授为通讯作者,许岚教授提供指导,上海科技大学为第一发表单位。
原文链接:https://dl.acm.org/doi/abs/10.1145/3394171.3413734。
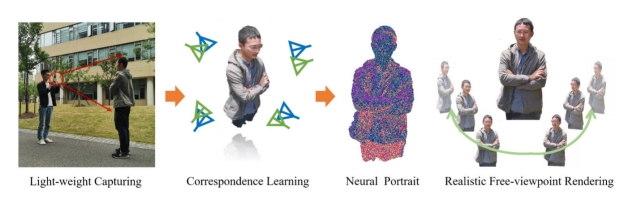
图| 实现任意视角的逼真渲染的Neural3D 系统
文章 LGNN: A Context-aware Line Segment Detector提出了一种新颖的实时线段检测方案--线图神经网络(LGNN)用以提取在结构上具有全局重要性的直线段。该方法使用深度卷积神经网络(DCNN)可以快速提出直线段,并使用图神经网(GNN)模块推理其连接性。具体而言,LGNN针对每个线段采用新的四元组表示,其中GNN模块将预测的候选对象用作顶点,并构造一个稀疏图以编译上下文的结构信息。与最新技术相比,LGNN可在不影响准确性的情况下实现接近实时的性能。LGNN进一步推动了对时间敏感的3D应用程序。对于输入的RGBD图片序列,课题组首先利用LGNN与RGB信息检测2D线段,其次,利用深度信息检测每张图片中的平面。基于2D-3D信息以及平面与线段关系的一致性,最终获取了场景的线框图。该工作由研究生孟权(第一作者)和研究生张家恺(第二作者)合作共同完成,虞晶怡教授为通讯作者,何旭明教授提供指导,上海科技大学为第一发表单位。
原文链接:https://dl.acm.org/doi/10.1145/3394171.3413784。
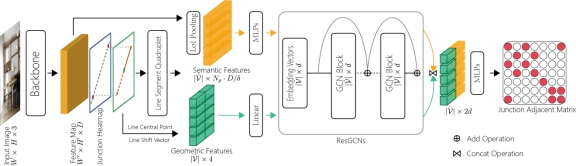
图| 语义和几何上下文感知的直线段检测模型架构
上海科技大学信息学院视觉与数据智能中心致力于通过学科领域的前沿研究,推动科研成果的转化和落地,切实解决行业“痛点”。以信息化培育新动能,以新动能推动新发展,中心鼓励学生以专业知识为基石进行科研创新和成果转化。学院本科毕业生吕文涛就是一个代表性的案例。他和同学一起创立的“岱悟智能”科技公司正致力于通过人工智能、机器人和可穿戴式设备,力求为建筑行业提供一体化智能工地的解决方案。未来,中心将继续贯彻学校的发展方针,瞄准科学前沿和产业需求,增加自主发展动力,加强产业协同攻关,推动人工智能新发展。

 沪公网安备 31011502006855号
沪公网安备 31011502006855号