
人机交互作为研究人与计算系统双向信息传递的交叉学科,随着多模态感知、生成式AI和脑机接口等技术的快速发展,如何构建既像与人对话般简单直观,又能可靠保护用户隐私的交互系统,已成为学界与产业界共同关注的焦点。作为全球HCI领域的旗舰会议(CCF A类),ACM CHI始终引领着人机协同进化的前沿探索。我有幸参加2025年4月26日至5月1日在日本横滨举办的CHI 2025会议,可以向其他学者汇报和交流我的研究成果。
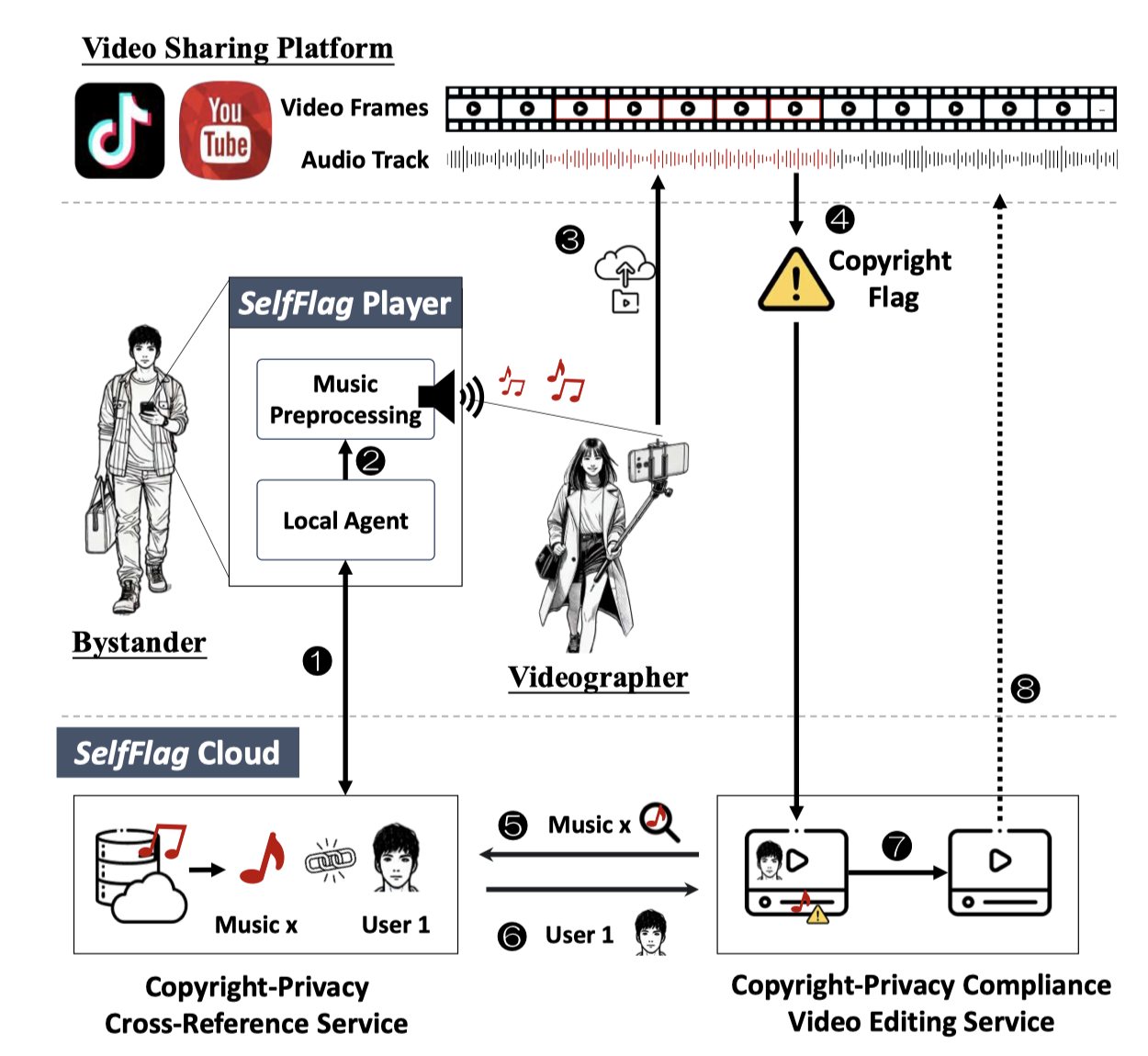
在互联网技术快速进步的推动下,视频共享平台已成为数十亿用户日常生活中不可或缺的一部分。然而,视频拍摄通常发生在公共场所,旁观者可能会在未经同意或无意录制的情况下出现在镜头的背景中,公开分享此类视频可能会暴露他们的个人信息。更令人担忧的是,现有解决方案多停留在事后举报阶段,受害者往往需要经历平均72小时的漫长等待,且需主动提交包括身份证明在内的复杂材料。这种被动式保护机制不仅效率低下,还给受害者带来二次伤害的风险。针对这一挑战,我们创新性地提出利用平台现有审核机制实现隐私保护,并开发了配套的自动化视频隐私处理工具。
在CHI会议的分会场“Risk and Privacy”,我就题为《Bystander Privacy in Video Sharing Era: Automated Consent Compliance through Platform Censorship》的研究论文进行学术汇报,系统阐述了SelfFlag技术的核心原理与创新优势。该技术通过设计可由旁观者携带的媒体信号装置,触发视频共享平台的自动化内容标记机制。为实现高效、优雅且非侵入式的隐私保护目标,我们对YouTube、TikTok等主流平台的审核规则进行系统性分析,最终选定版权音乐作为信号载体,并建立科学的曲目筛选标准。此外,我们设计的超声波扬声器可以在人类听不见的频率范围内播放版权音乐,使该方案即使在安静的环境中也能有效运行。
SelfFlag系统的工作流程
在汇报后的问答环节中,两位学者向我提出了非常具有启发性的问题。
第一个问题是:这样的技术还能应用在未来的哪些方向呢?这个问题并非是问我们系统的实际应用场景,而是问像这种利用平台现有规则进行隐私保护的方法论,还能扩展到哪些研究方向中,不仅仅是视频领域。这个问题十分具有挑战性,虽然我当时没有给予对方一个很好的答复,但是启发了我对未来课题的探索方向。在汇报结束之后,也有其他人对这个问题感兴趣,和我进行了深入交流。根据他们对新兴数据驱动技术的控制和隐私问题的研究经验,提议我可以从更多实际场景中的问题出发,用技术解决生活中的问题。
第二个问题是:你们是如何把视频中的旁观者消除的?是否已经实现了这样一个视频处理系统?针对这个问题,我解释道,我们使用了名为“Video Inpainting”的深度学习技术,可以在进行旁观者人脸识别之后,生成对应的动态遮罩,从而在保持视频背景连贯的情况下,自然消除旁观者。目前该系统已在云端完成部署,具体架构可以参考论文中SelfFlag平台的设计方案。
会议期间,通过参与Interactivity展区与Late Breaking Work环节,我有幸接触到多项体现人机交互技术多元化应用的创新研究。尤为值得关注的是面向儿童教育领域的设计实践:南方科技大学团队开发的智能玩具系统,通过集成压力传感模块与实时动态反馈机制,帮助自闭症儿童在游戏互动中逐步提升社交认知能力,该方案已在幼儿园开展教学实践。另有研究团队基于儿童认知特点开发交互工具,将复杂的隐私政策转化为可视化叙事——例如通过'魔法饼干'的拟人化设计,帮助儿童理解网络cookie的数据追踪本质。此外,东京大学团队研发的麦克风增强附件颇具实用价值,其通过声学结构优化设计,使40分贝以下的耳语音量也能被手机清晰捕捉,有效解决了公共场合远程会议中隐私保护与通信质量的矛盾问题。这些创新成果不仅实现了技术落地,更彰显了人机交互研究对社会需求的深度回应。
本次学术经历进一步强化了我的研究认知:优秀的人机交互系统需在技术创新、用户体验与社会价值三者间建立动态平衡。我未来将持续优化SelfFlag系统的实时处理效能与跨平台适应性,重点探索其在直播场景中的即时隐私保护应用,致力于构建更安全、更人性化的数字交互环境。

参加会议的照片

 沪公网安备 31011502006855号
沪公网安备 31011502006855号


