
Recently, Assistant Professor Tu Kewei's research group from the Vision and Data Intelligence Center of SIST has had 8 papers accepted by the 59th Annual Meeting of the Association for Computational Linguistics (ACL 2021) with 7 papers in the Main Conference and 1 paper in Findings of ACL. ACL is the top conference in the field of natural language processing (NLP) and one of the most important conferences in the field of artificial intelligence. The acceptance rate of ACL 2021 is 21%.
The Main Conference papers cover research directions including unsupervised text parsing, (monolingual) structured prediction, and cross-lingual structured prediction. Following are introductions to the 7 Main Conference papers.
Unsupervised parsing aims to train a text parser from unannotated texts alone. Acquiring training text with high-quality annotations is time and labor consuming. Unsupervised parsing is the technical basis to circumvent this challenge. Two of the papers study unsupervised syntactic parsing and unsupervised discourse parsing respectively.
1. Neural Bi-Lexicalized PCFG Induction
In this paper, Dr. Tu’s group studied unsupervised dependency and constituency parsing based on bi-lexicalized probabilistic context-free grammars (PCFGs). Previous work in this field made a strong independence to decrease the time complexity of lexicalized PCFGs, which ignores bi-lexical dependencies. Dr. Tu’s group proposed to parameterize bi-lexicalized PCFGs using tensor decomposition, so that they could model bi-lexicalized dependencies and decrease complexities at the same time. Yang Songlin, first year Master student in Dr. Tu's group, is the first author of the paper, University of Edinburgh is the collaboration university, and Dr. Tu is the corresponding author.
Paper link: http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21pcfg.pdf

Figure 1. Original bi-lexicalized PCFGs (left), previous work (middle) and the proposed method (right).
2. Adapting Unsupervised Syntactic Parsing Methodology for Discourse Dependency Parsing
In this paper, Dr. Tu’s group investigated how to adapt unsupervised dependency parsing models to dependency discourse parsing. Discourse parsing aims to find how text spans in a document relate to each other. So far there has been little research in unsupervised discourse dependency parsing. Dr. Tu’s group proposed a simple yet effective method to adapt unsupervised syntactic dependency parsing methodology for unsupervised discourse dependency parsing. They applied the method to adapt two state-of-the-art unsupervised syntactic dependency parsing methods, and further extended the adapted methods to the semi-supervised and supervised settings. Zhang Liwen, third year PhD student in Dr. Tu's group, is the first author of the paper, Beijing Institute for General Artificial Intelligence is the collaboration institute, and Dr. Tu is the corresponding author.
Paper link: http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21disc.pdf
Structured prediction refers to the machine learning subfield in which the output has structures (e.g., chains, trees, graphs). Many important tasks in NLP belong to structured prediction, such as the classically named entity recognition task (i.e., recognizing entities such as persons and locations in a sentence). Three of the papers try to improve structured prediction from different perspectives.
1. Automated Concatenation of Embeddings for Structured Prediction
Dr. Tu’s group studied an approach that can automatically concatenate embeddings for structured prediction tasks. Recent work found that better word representations can be obtained by concatenating different types of embeddings, but getting the best concatenation of embeddings is a very difficult problem. In this paper, Dr. Tu’s group proposed Automated Concatenation of Embeddings (ACE) to automate the process to find better concatenations of embeddings for structured prediction tasks, based on a formulation inspired by recent progress on neural architecture search. ACE uses a controller to sample a concatenation of embeddings, computes a reward from the accuracy of a task model based on the embedding concatenation, and applies reinforcement learning to optimize the parameters of the controller. Wang Xinyu, first year PhD candidate in Dr. Tu's group, is the first author of the paper, Alibaba DAMO Academy is the collaboration institute, and Dr. Tu is the corresponding author.
Paper link:http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21ace.pdf
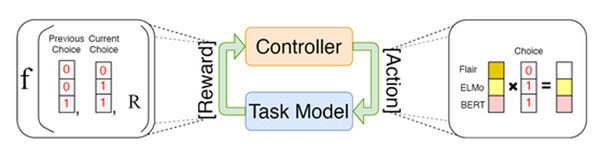
Figure 2. The training framework of ACE.
2. Improving Named Entity Recognition by Retrieving External Contexts and Cooperative Learning
Dr. Tu’s group studied an approach that improved the accuracy of named entity recognition through retrieving related texts of the input sentence and used cooperative learning to further improve the model accuracy. Recent advances in named entity recognition have shown that document-level contexts can significantly improve model performance, but in many scenarios such contexts are not available. In this paper, Dr. Tu’s group proposed to find external contexts of a sentence by retrieving and selecting a set of semantically relevant texts through a search engine, with the original sentence as the query. Furthermore, they can improve the model performance of both input views by cooperative learning, which encourages the two input views to produce similar contextual representations or output label distributions.
Paper link:http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21ner.pdf

Figure 3. The framework of the proposed approach.
3. Structural Knowledge Distillation: Tractably Distilling Information for Structured Predictor
In this paper, Dr. Tu’s group proposed a general knowledge distillation approach for structured prediction problems. Structural knowledge distillation transfers structural information between structured predictors. The output space of structured prediction tasks is exponential in size and hence the objective function of structural knowledge distillation is intractable to compute and optimize directly. Dr. Tu's group proposed, under certain conditions, a factorized form of the structural knowledge distillation objective by utilizing the fact that almost all the structured prediction models factorize the scoring function of the output structure into scores of substructures. In this way, the objective becomes tractable to compute and optimize.
Paper link:http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21kd.pdf
Cross-lingual structured prediction refers to using data and models of one or more (rich-resource) languages to help the learning of a structured prediction model of a (low-resource) target language. Such cross-lingual transfer is an effective way to train high-quality models for minority languages that lack data and annotation resources. The following two papers study the zero-shot and few-shot scenarios of the target language respectively.
1. Risk Minimization for Zero-shot Sequence Labeling
In this paper, Dr. Tu’s group investigated cross-lingual zero-shot sequence labeling, i.e., building a sequence labeler without annotated datasets for the target language. They proposed a novel unified framework for zero-shot sequence labeling with minimum risk training and designed a new decomposable risk function that models the relations between the predicted labels in the source models and the true labels. By making the risk function trainable, they drew a connection between minimum risk training and latent variable model learning. They also proposed a unified learning algorithm based on the expectation maximization (EM) algorithm. Hu Zechuan, second year Master student in Dr. Tu's group, is the first author of the paper.
Paper link: http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21rm.pdf
2. Multi-View Cross-Lingual Structured Prediction with Minimum Supervision
In this paper, Dr. Tu’s group investigated cross-lingual structured prediction with multiple source languages and minimum annotated data of the target language. They proposed a multi-view framework that leveraged a small number of labeled target sentences to effectively combine multiple source models into an aggregated source view at different granularity levels (language, sentence, or substructure) and transferred knowledge from the source view to a target view based on a task-specific model. By encouraging the two views to interact with each other, their framework can dynamically adjust the confidence level of each source model and improve the performance of both views during training. Hu Zechuan, first year Master student in Dr. Tu's group, is the first author of the paper.
Paper link: http://faculty.sist.shanghaitech.edu.cn/faculty/tukw/acl21mv.pdf
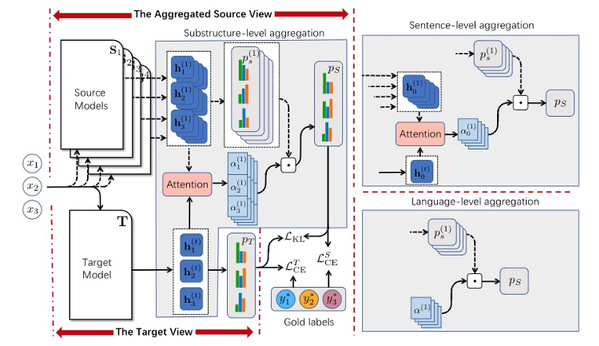
Figure 4.The proposed framework

 沪公网安备 31011502006855号
沪公网安备 31011502006855号


