
Prof. Gao Shenghua’s research group published four papers at IEEE Conference on Computer Vision and Pattern Recognition (CVPR2021), showing their recent achievements in related fields. CVPR is an annual academic conference hosted by IEEE, and one of the three top academic conferences in the field of computer vision(CVPR, ICCV, ECCV), and enjoys a high reputation in the world. According to Google Scholar Metrics, the top conference CVPR ranks fifth among all conferences and journals included by Google.
Layout-Guided Novel View Synthesis from a Single Indoor Panorama
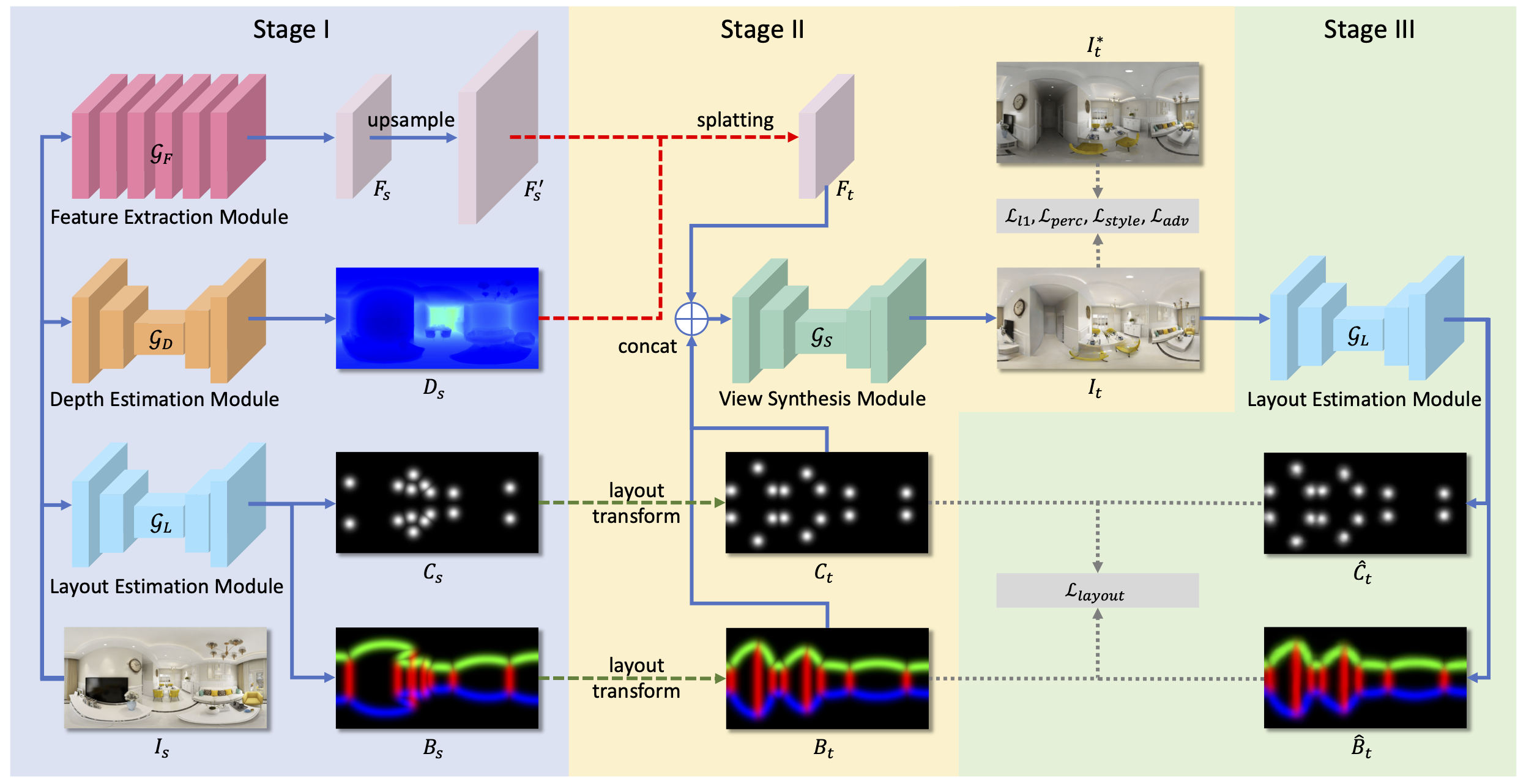
Existing view synthesis methods mainly focus on the perspective images and have shown promising results. However, due to the limited field-of-view of the pinhole camera, the performance quickly degrades when large camera movements are adopted. In this research, Gao's group makes the first attempt to generate novel views from a single indoor panorama and takes the large camera translations into consideration. To tackle this challenging problem, the reseachers first use Convolutional Neural Networks (CNNs) to extract the deep features and estimate the depth map from the source-view image. Then, the method leverages the room layout prior, a strong structural constraint of the indoor scene, to guide the generation of target views. More concretely, the method estimates the room layout in the source view and transforms it into the target viewpoint as guidance. Meanwhile, the method also constrains the room layout of the generated target-view images to enforce geometric consistency. To validate the effectiveness of the method, Gao's group further build a large-scale photorealistic dataset containing both small and large camera translations. The experimental results on the challenging dataset demonstrate that the proposed method achieves state-of-the-art performance on this task. SIST MS student Xu Jiale is the first author, and Prof. Gao Shenghua is the corresponding author.
Prior Based Human Completion
Human images completion is an important subproblem in image inpainting. Human completion aims to recover the corrupted single person image and generate plausible results. However, few work has done along this direction. Thus, we propose prior based human body completion model.
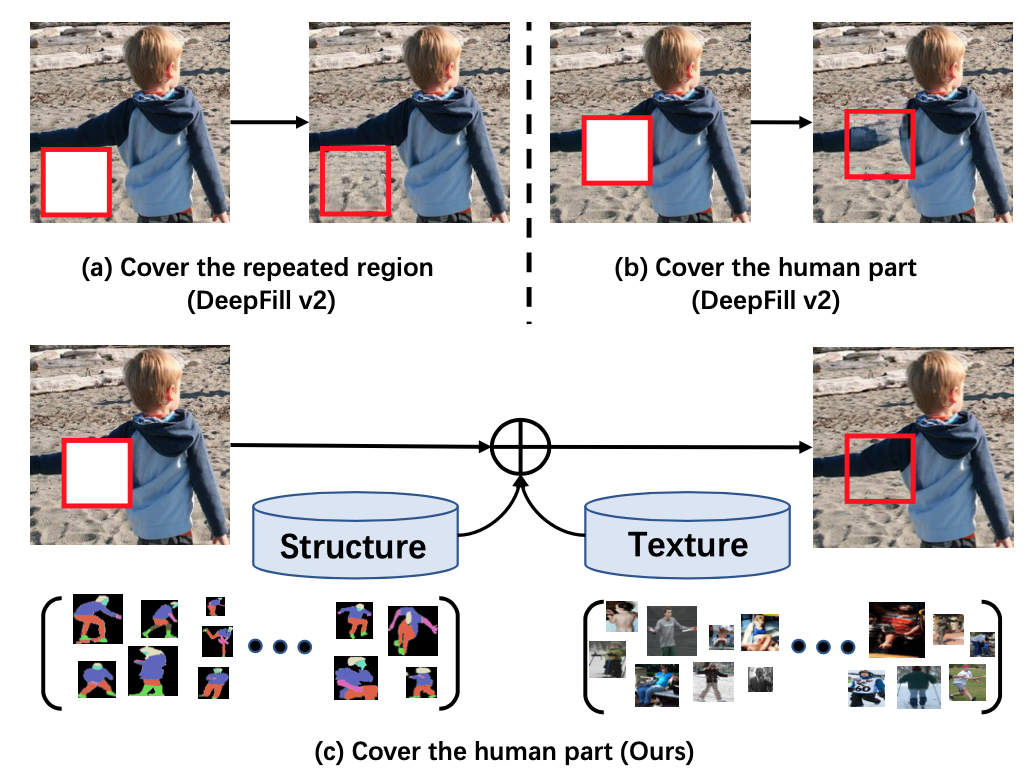
Structure information is essential for the model to understand the foreground and background in images. While, most existing methods implicitly encode this information by forcing the model to learn it. Therefore, we first propose to leverage semantic segmentation maps as prior to characterize human body structure. The structural prior not only explicitly guides the human part completion, but also provides semantic information in extracted feature maps to recover the human structure. Besides, we design a memory bank module, which embedded into the model to provide the structure-texture correlation prior. With the aid of memory bank, the model could further inpaint vivid textures. The model consists of three stages. In the first stage, we maintain the memory bank module and embedded it into the next two stages. In the second and third stages, the model would recover the reasonable human structure and plausible textures.
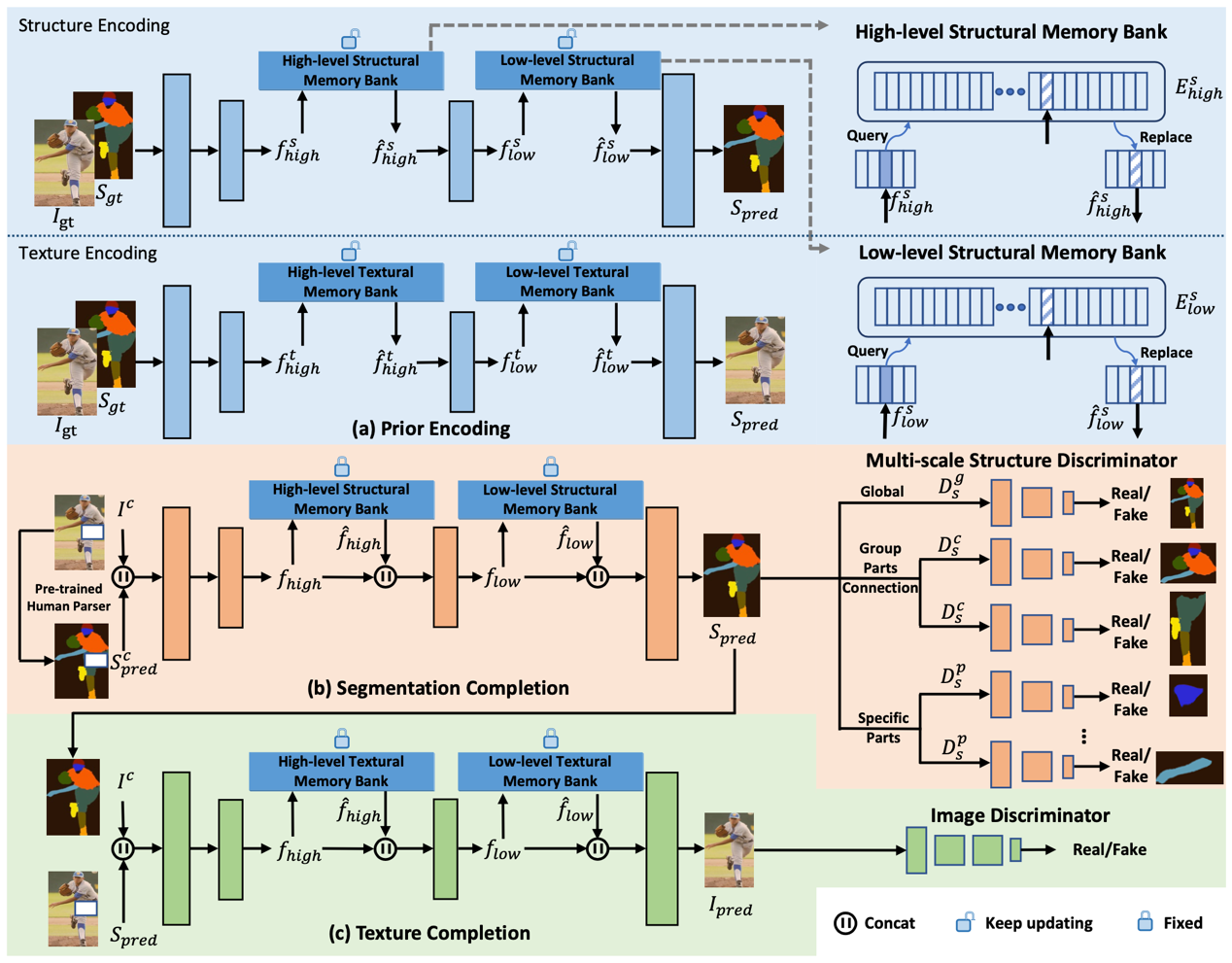
The extensive experiment on two large scale datasets (LIP and ChictopiaPlus) verifies the effectiveness of our model. Master student Zhao Zibo is the first author and Prof. Gao Shenghua is the corresponding author.
Landmark Feature Convolution For Visual Grounding
Visual grounding, aiming to localize an object described by an expression, is one of the fundamental visual-language problems and the key to achieving human-computer interaction. Humans often refer to an object by describing their relationships with other entities, e.g., 'laptop on the table,' and understanding their relationships is vital to comprehend referential expressions. Since the distances between two entities can be arbitrary and direction-related, we hypothesis that we should consider (i) long-range (ii) and direction-aware context.
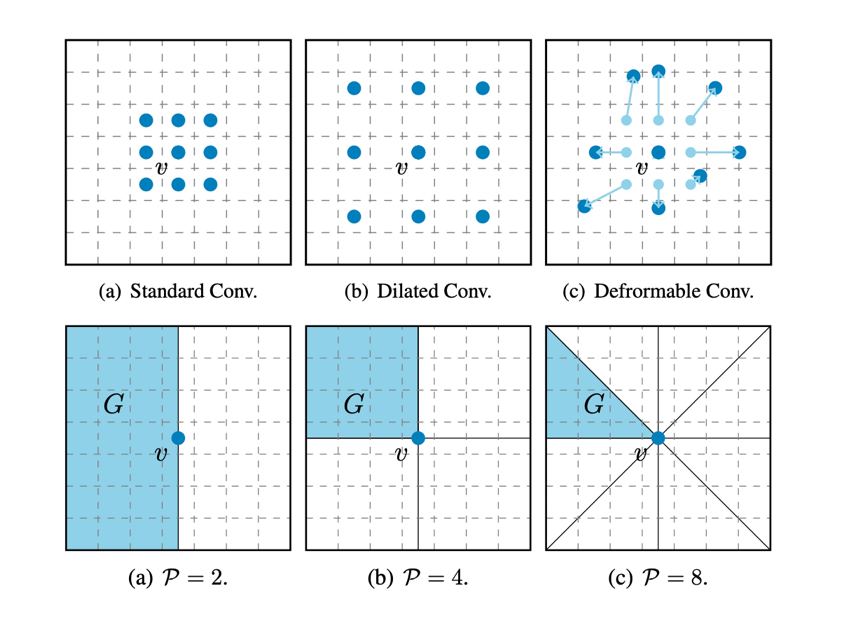
Long-range modeling is a long-standing but unsolved problem in computer vision. Existing convolution operations have the apparent limitation of the receptive field since they sample a fixed number of locations for aggregation. To illustrate, given the same number of parameters, a convolution's receptive field is either dense but small (standard convolution) or large but sparse (dilated convolution). To this end, we propose convolution by sampling regions. For each location, we part the whole feature map based on the current location and update the representation by aggregating the sub-regions so that the operator has a global receptive field. Experiments show that the proposed convolution is advantageous to related modules in terms of efficiency or effectiveness. We also achieve competitive results on four benchmark datasets by using the proposed operators. Huang Binbin (2020 class master student) is the first author, and his mentor, prof. Gao Shenghua is the corresponding author.
Learning to Recommend Frame for Interactive Video Object Segmentation in the Wild
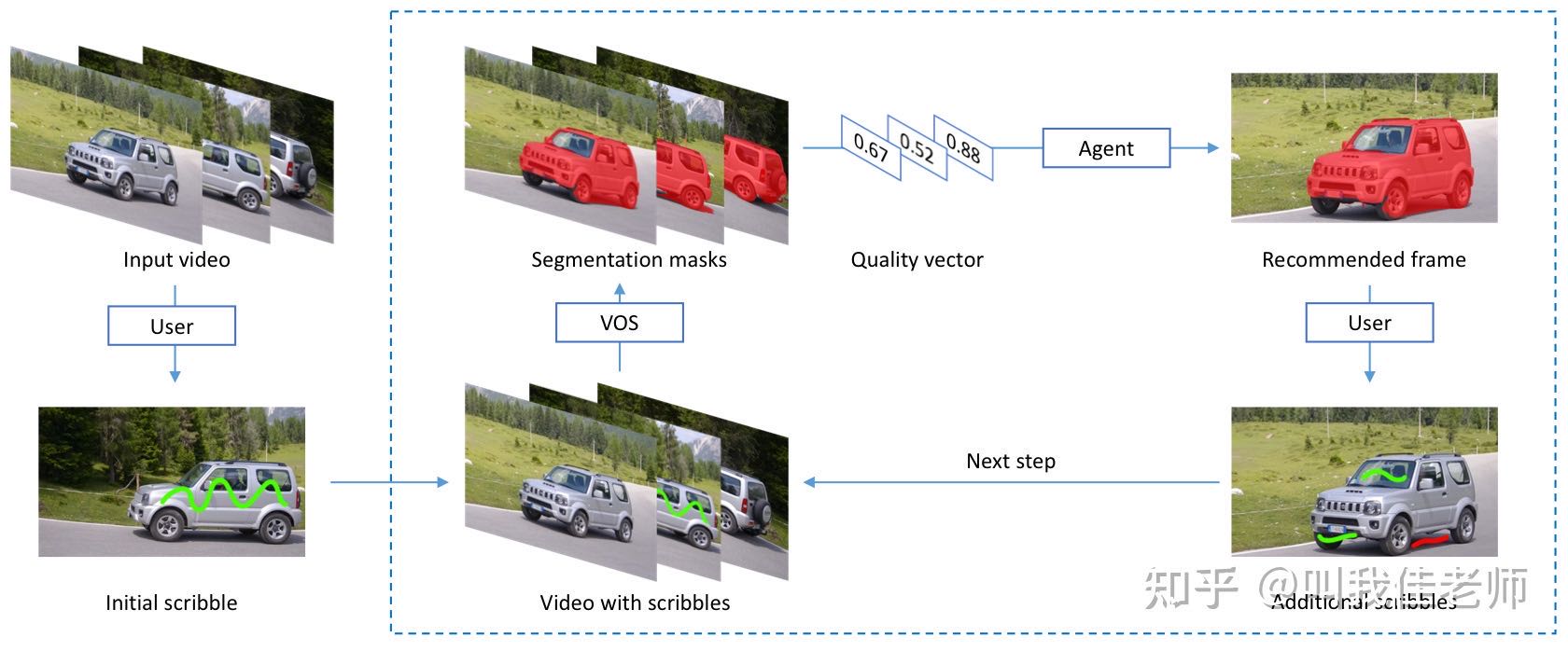
To reduce the cost of human annotations, interactive video object segmentation (VOS for short) aims to achieve promising results with a few human supervisions. The author hypothesis that it is vital to recommend keyframes for interactive video object segmentation to improving the overall quality.
This paper formulates the frame selection problem in the interactive VOS as a Markov Decision Process, where an agent is learned to recommend the frame under a deep reinforcement learning framework. The learned agent can automatically determine the most valuable frame, making the interactive setting more practical in the wild. Experimental results on the public datasets show the effectiveness of our learned agent without any changes to the underlying VOS algorithms, and the learned agent can surpass human annotators in terms of accuracy and efficiency. Visiting student Yin Zhaoyuan is the first author, and MS Zheng Jia who has graduated from ShanghaiTech last year is the second author.

 沪公网安备 31011502006855号
沪公网安备 31011502006855号


