
Prof. XuLan’s research group in VDI Center targets top-tier research at the intersection of computer vision, computer graphics and computational photography. The group is committed to the research fields of human digital twins, light field reconstruction, artificial reality and artificial intelligence for digital entertainment. The research mission is to enable motion capture and perceptual understanding of human-centric dynamic scenes. Recently, the research group published two papers at the IEEE Conference on Computer Vision and Pattern Recognition 2021, fully demonstrating their latest research results in the field of computer vision. CVPR is IEEE’s annual international academic conference and one of the three top academic conferences in the field of computer vision. It enjoys a high reputation internationally. According to the statistics of Google Scholar Metrics as of June last year, CVPR ranks fifth in comprehensive influence among all Google journals and conferences.
NeuralHumanFVV: Real-Time Neural Volumetric Human Performance Rendering using RGB Cameras
4D reconstruction and rendering of human activities is critical for immersive VR/AR experience. Recent advances still fail to recover fine geometry and texture results with the level of detail present in the input images from sparse multi-view RGB cameras. We propose NeuralHumanFVV, a real-time neural human performance capture and rendering system to generate both high-quality geometry and photo-realistic texture of human activities in arbitrary novel views. We propose a neural geometry generation scheme with a hierarchical sampling strategy for real-time implicit geometry inference, as well as a novel neural blending scheme to generate high resolution (e.g., 1k) and photo-realistic texture results in the novel views. Furthermore, we adopt neural normal blending to enhance geometry details and formulate our neural geometry and texture rendering into a multi-task learning framework. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality geometry and photo-realistic free view-point reconstruction for challenging human performances.
The 2018 graduated student SuoXin is the first author, Professor Xu Lan is the corresponding author.
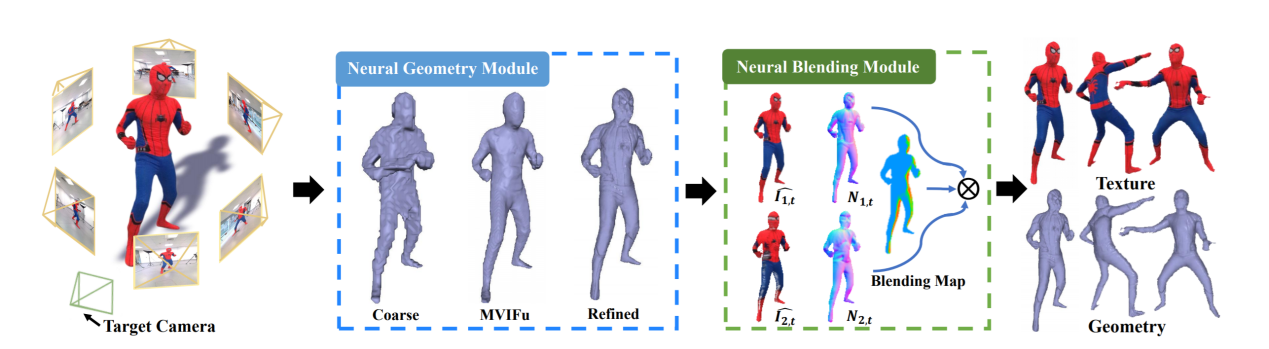
The pipeline of NeuralHumanFVV consists of neural geometry module and neural blending module

The results
ChallenCap: Monocular 3D Capture of Challenging Human Performances using Multi-Modal References
Capturing challenging human motions is critical for numerous applications, but it suffers from complex motion patterns and severe self-occlusion under the monocular setting. In this paper, we propose ChallenCap -- a template-based approach to capture challenging 3D human motions using a single RGB camera in a novel learning-and-optimization framework, with the aid of multi-modal references. We propose a hybrid motion inference stage with a generation network, which utilizes a temporal encoder-decoder to extract the motion details from the pair-wise sparse-view reference, as well as a motion discriminator to utilize the unpaired marker-based references to extract specific challenging motion characteristics in a data-driven manner. We further adopt a robust motion optimization stage to increase the tracking accuracy, by jointly utilizing the learned motion details from the supervised multi-modal references as well as the reliable motion hints from the input image reference. Extensive experiments on our new challenging motion dataset demonstrate the effectiveness and robustness of our approach to capture challenging human motions.
The 2018 graduated student He Yannanis the first author, Professor Xu Lan is the corresponding author.
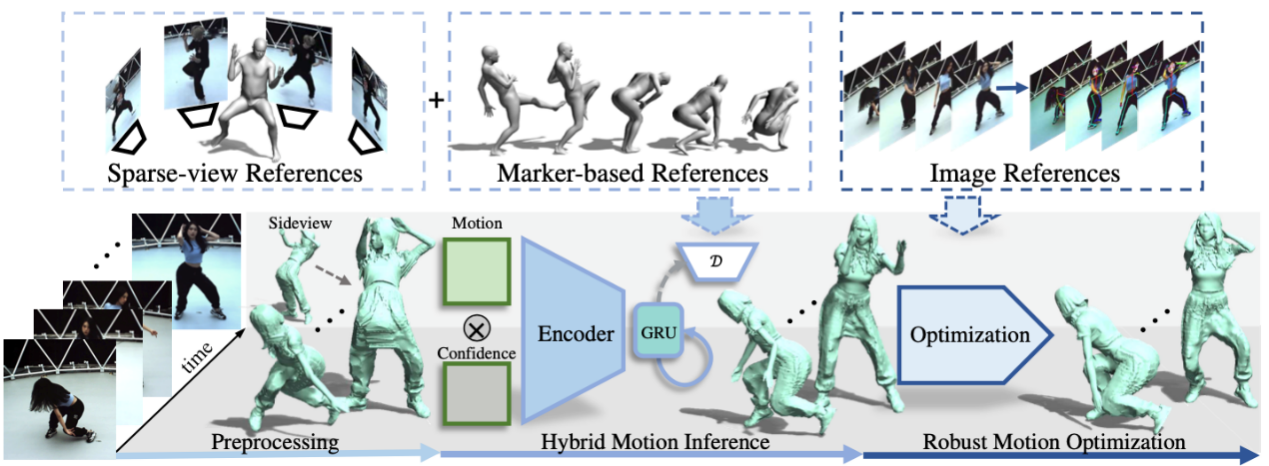
The pipeline of ChallenCap with multi-modal references

The results

 沪公网安备 31011502006855号
沪公网安备 31011502006855号


