
Recently, Dr. Kewei Tu's research group at the Vision and Data Intelligence Center of the School of Information Science and Technology, ShanghaiTech University published three papers at the main conference of EMNLP 2020, as well as four papers at the extended paper collection EMNLP Findings. Empirical Methods in Natural Language Processing (EMNLP) is one of the top three conferences (ACL, EMNLP and NAACL) in the field of natural language processing. It enjoys a high international reputation and is among the top 10 journals and conferences in artificial intelligence according to Google Scholar Metrics. The acceptance rate of EMNLP 2020 is 22%.
In the main conference paper 'Cold-start and Interpretability: Turning Regular Expressions into Trainable Recurrent Neural Networks', we propose a method to convert regular expressions to a recurrent neural network. Regular expressions (RE) are one of the most widely used symbolic rules in natural language processing. They have good interpretability and high precision, but cannot learn from data to improve their performance as neural networks do. In comparison, neural networks have amazing accuracy when trained with sufficient labeled data, but do not work well when labeled data are scarce. In addition, neural networks are hard to interpret and cannot easily integrate external knowledge. Dr. Tu’s group propose to convert the non-deterministic finite automata (NFAs) that are equivalent to REs to a trainable recurrent neural network, thus combining the advantages of symbolic rules and neural networks. The experiments on text classification show that the neural network converted from the RE system has similar performance to REs and much better performance than randomly initialized neural networks when there is no data; it has clear advantage in the low-resource scenarios; and it is comparable to neural networks when there are sufficient data. JiangChengyue, a class 2019 master student in Dr. Tu's group, is the first author of the paper, Leyan Inc. is the collaborator institute, and Dr. Tu is the corresponding author. The project is supported by Leyan Inc. and the National Natural Science Foundation of China.
Paper link: https://www.aclweb.org/anthology/2020.emnlp-main.258/
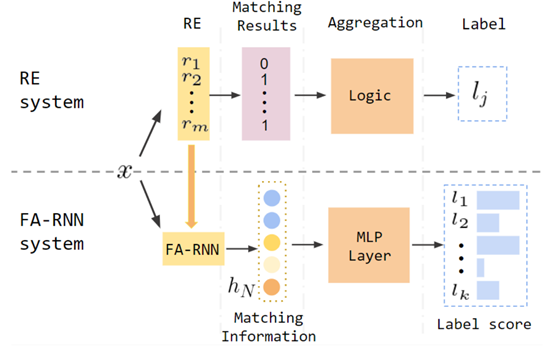
Figure | The framework proposed by the paper
In the main conference paper 'Adversarial Attack and Defense of Structured Prediction Models', we study adversarial example generation on natural language structured prediction problems. Adversarial examples are those that the predictor is prone to make errors and finding adversarial samples can help improve the accuracy and robustness of the predictor. Most existing methods of generating adversarial examples only work for classification tasks in computer vision and natural language processing and are not designed for structured prediction tasks. Prof Tu’s research group propose a reinforcement learning based framework to generate adversarial examples, which surpasses previous methods and has the advantages of being a blackbox and online attacker and capable of generating variable-length sentences. HanWenjuan, a 2020 PhD alumna (now a postdoctoral fellow at the National University of Singapore), and ZhangLiwen , a class 2018 PhD student in Dr. Tu's research group, are the co-first authors of this paper, and Dr. Tu is the corresponding author. The project is supported by the National Natural Science Foundation of China.
Paper link: https://www.aclweb.org/anthology/2020.emnlp-main.182/
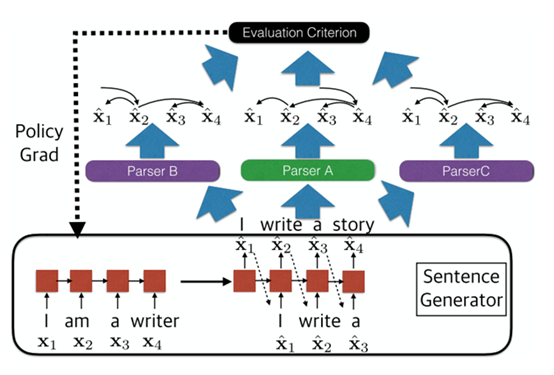
Figure | The framework proposed by the paper
In the main conference paper 'AIN: Fast and Accurate Sequence Labeling with Approximate Inference Network', we study a fast parallelizable method for sequence labeling. Sequence labeling is a fundamental task in natural language processing, widely used in real-world applications such as search advertisement recommendation and e-commerce. In these applications, we sometimes require very fast sequence labelers to handle user requests and promote user experience. One of the main approaches to sequence labeling is the CRF model. CRF inference algorithms such as the Viterbi algorithm contain sequential computation and cannot achieve word-level parallelization. Dr. Tu’s research group apply Mean-Field Variational Inference (MFVI) to approximately decode the CRF model, which iteratively passes messages among neighboring labels to update their predicted distributions until convergence. They turn MFVI into a recurrent neural network in which word-level parallelization becomes possible. Empirical results show that the approach achieves almost the same average accuracy as CRF and is significantly faster than the traditional CRF approach. WangXinyu, a class 2020 PhD student in Dr. Tu's group, is the first author of the paper, Alibaba DAMO Academy is the collaborator institute, and Dr. Tu is the corresponding author. The project is supported by Alibaba DAMO Academy and the National Natural Science Foundation of China.
Paper link: https://www.aclweb.org/anthology/2020.emnlp-main.485/
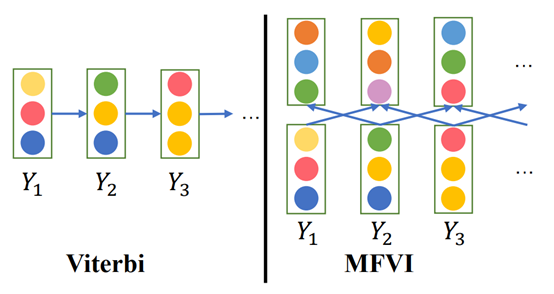
Figure | A comparison of the traditional Viterbi algorithm (left) and the algorithm proposed by this paper (right)

 沪公网安备 31011502006855号
沪公网安备 31011502006855号


