
As one of the most popular fields in artificial intelligence, deep neural network (DNN) is a promising approach to realize many AI tasks such as speech recognition, image classification and autonomous driving. At the same time, with advances in the technology of edge computing and internet of things, it is necessary to deploy pretrained DNN models at the edge of networks and on the terminal devices. However, these DNN models usually contain a massive number of parameters, proving a huge challenge for the terminal devices having limited computation capability to carry out the heavy computation tasks as needed to deploy DNNs.
Network sparsification is regarded as an efficient method for DNN model compression, and can be utilized to conquer this computation problem. The essence of network sparsification is to simplify the weight parameters in DNN layers, without influencing the DNN performance thus reducing the number of operations in the memories of terminal devices.
Recently, SIST Assistant Professor Wang Hao’s research group developed a novel trimming approach to determine the redundant parameters of the trained DNN in a layer-wise manner to produce a compact neural network, and their achievement was published in the journal IEEE Transactions on Computers in an article entitled “A Proximal Iteratively Reweighted Approach for Efficient Network Sparsification.”
The trimming method that Wang's group developed is a log-sum minimization approach to prune a large already-trained neural network in a layer-wise manner to produce a compact model. This approach optimizes the memory footprint and reduces the number of operational numbers for model inference in the edge devices. The process of trimming and optimization involves iterative computations, and, in order to reduce the trimming time, a practical criterion was set up in the iterations for their early termination. Finally, this algorithm was backed up by the global convergence analysis and complexity analysis.
The first author of this work is Prof. Wang Hao.
Read more at:https://ieeexplore.ieee.org/document/9291425/authors#authors
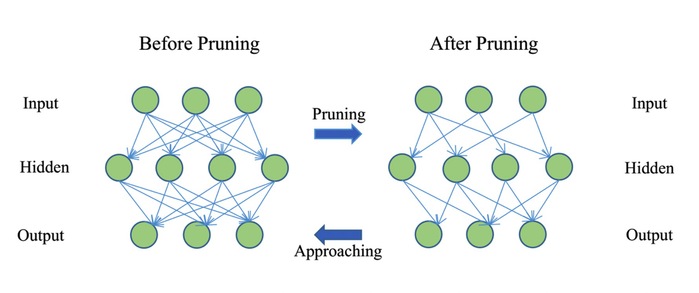
Fig. 1: Illustration of weight pruning in a layer-wise manner for a network with 1 hidden layer. Sparse connections provide fewer weight connections while the output of the pruned model still approaches the performance of the unpruned one
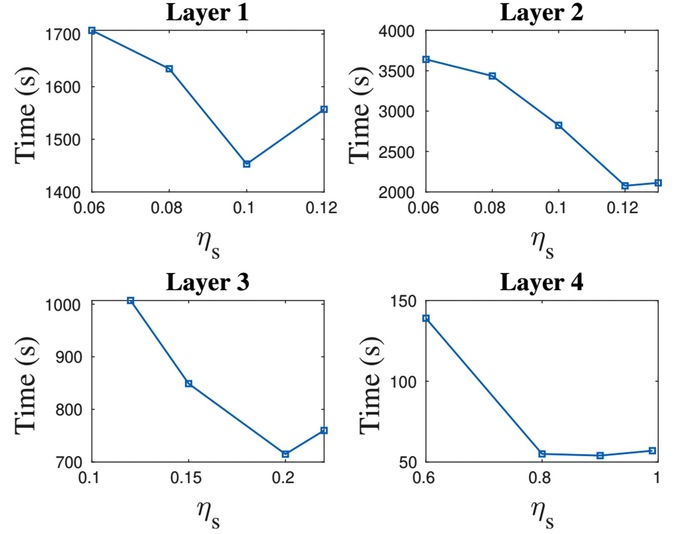
Fig. 2: Pruning time of each layer under different ηs

 沪公网安备 31011502006855号
沪公网安备 31011502006855号


