
Recently, four papers from SIST were accepted by International Conference on Computer Vision (ICCV) 2019. Among them, two papers come from Professor He Xuming’s research group, one paper comes from Professor Gao Shenghua’s research group and one paper comes from Professor Yu Jingyi’s research group.
The International Conference on Computer Vision (ICCV) is one of the highest-level international academic conferences in the field of computer vision. It is organized by the IEEE (Institute of Electrical and Electronics Engineers) and held every two years worldwide. This year, ICCV 2019 received a total of 4,350 paper submissions, and only 1050 papers were accepted. The acceptance rate was 24%, of which 850 were poster and 200 were oral.
Two papers were accepted from Professor He Xuming’s research group. The article Pose-aware Multi-level Feature Network for Human Object Interaction Detection proposes a novel human-object interaction detection model. Reasoning human object interactions is a core problem in human-centric scene understanding and detecting such relations poses a unique challenge to vision systems due to large variations in human-object configurations, multiple co-occurring relation instances and subtle visual difference between relation categories. To address those challenges, we propose a multi-level relation detection strategy that utilizes human pose cues to capture global spatial configurations of relations and as an attention mechanism to dynamically zoom into relevant regions at human part level. Specifically, we develop a multi-branch deep network to learn a pose-augmented relation representation at three semantic levels, incorporating interaction context, object features and detailed semantic part cues. As a result, our approach is capable of generating robust predictions on fine-grained human object interactions with interpretable outputs. Extensive experimental evaluations on public benchmarks show that our model outperforms prior methods by a considerable margin, demonstrating its efficacy in handling complex scenes.
The work was only one of 4% of oral presentations accepted by the conference. Master’s degree student Wan Bo and PhD student Zhou Desen are the first authors of the paper, and Professor He Xuming is the corresponding author.
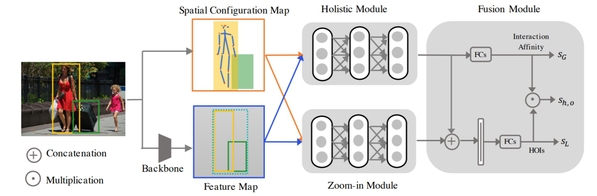
Fig.1: Overview of our framework: For a pair of human-object proposals and related human pose, Backbone Module aims to prepare convolution feature map and Spatial Configuration Map (SCM). Holistic Module generates object-level features and Zoom-in Module captures part-level features. Finally Fusion Module combines object-level and part-level cues to predict final scores for HOI categories.
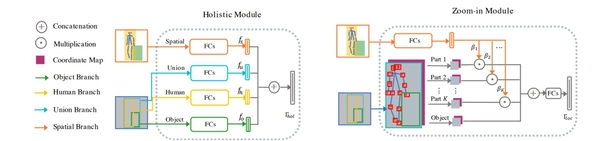
Fig 2. The structure of holistic module and zoom-in module. Holistic module includes human, object, union and spatial branches. Zoom-in module uses human part information and attention mechanism to capture more details
Dynamic Context Correspondence Network for Semantic Alignment,” studies semantic alignment tasks in order to find dense correspondence between different objects belonging to the same category. The goal of this work is to combine global semantic contexts in a flexible way to overcome the limitations of previous work relying on local semantic representations. This work first proposes a context-aware semantic representation that combines spatial layout to make a powerful distinction for local ambiguity. Then, the paper proposes a dynamic fusion strategy based on attention mechanism, which combines the advantages of local and context features by combining semantic cues from multiple scales. The article demonstrates its proposed strategy by designing an end-to-end learnable deep network called Dynamic Context Correspondence Network (DCCNet). In order to train the network, the article uses multiple auxiliary task losses to improve the efficiency of the weak supervised learning process. Master’s degree student Huang Shuaiyi is the first author of the paper, and Professor He Xuming is the corresponding author.
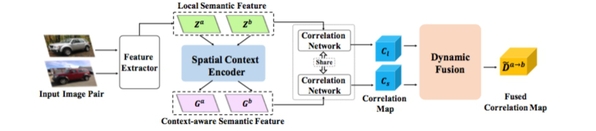
Fig 3. Overview of DCCNet. The proposed DCCNet consists of three main modules: a spatial context encoder, a correlaton network and a dynamic fusion network, which are used to produce a fused correlation map.
Fig 4. Overview of Spatial Context Encoder. Spatial context encoder generates context-aware features from local conv features.

These two scientific research results were supported by Shanghai NSF Grant (No. 18ZR1425100) and NSFC Grant (No. 61703195).
One paper was received from Professor Gao Shenghua's research group. “Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis” proposes a unified framework for tasks of human motion imitation, appearance transfer, and novel view synthesis. It contains three parts, Body Mesh Recovery, Flow Transformation, and Generative Adversarial Network. As human motion imitation, for example, the Body Mesh Recovery firstly estimates the 3D body mesh of the source image (B) and the reference image (A) and consequently extracts the visible textures of the source image (B). Then, a rendered synthetic human image is composed of the shape parameters and textures of the source image (B) and the pose parameters of the reference image (A). While the rendered synthetic human image is not realistic-looking because it only contains the nude body mesh (without the mesh of hair and clothes) and the visible textures. To solve these problems, at the last stage, a Generative Adversarial Network (GAN) is used to refine the rendered synthetic human image and make it more realistic-looking. This work was completed under a collaboration of Professor Gao Shenghua with researchers Ma Lin and Luo Wenhan at Tencent’s AI Lab. Professor Gao Shenghua ’s PhD student Liu Wen and Master’s degree student Piao Zhixin share an equal contribution.
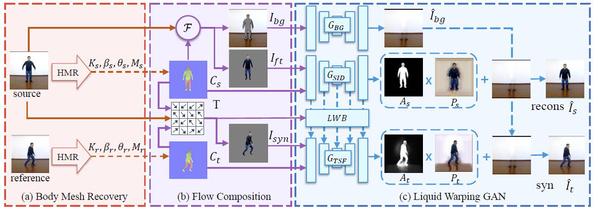
Figure 5: The whole training pipeline. It contains three parts, (a) Body Mesh Recovery, (b) Flow Transformation Computation, and (c) Generative Adversarial Network (GAN).
One paper was received from Professor Yu Jingyi’s research group. “Photo-Realistic Facial Details Synthesis from Single Image” presents a single-image 3D face synthesis technique that can handle challenging facial expressions while recovering fine geometric details. This technique employs expression analysis for proxy face geometry generation and combines supervised and unsupervised learning for facial detail synthesis. On proxy generation, this work conducts emotion prediction to determine a new expression-informed proxy. On detail synthesis, they present a Deep Facial Detail Net (DFDN) based on Conditional Generative Adversarial Net (CGAN) that employs both geometry and appearance loss functions. For geometry, they capture 366 high-quality 3D scans from 122 different subjects under three facial expressions. For appearance, they use additional 163K in-the-wild face images and apply image-based rendering to accommodate lighting variations. Comprehensive experiments demonstrate that this framework can produce high-quality 3D faces with realistic details under challenging facial expressions.
The work was accepted as an oral presentation. The students Chen Anpei and Chen Zhang are the first authors of the paper, and Professor Yu Jingyi is the corresponding author.

Figure 6: Algorithm processing pipeline. Top: training stage for (a) emotion-driven proxy generation and (b) facial detail synthesis. Bottom: testing stage for an input image.

 沪公网安备 31011502006855号
沪公网安备 31011502006855号


