近期,上海科技大学信息科学与技术学院郑杰课题组与合作者在《自然·通讯》(Nature Communications)发表了题为“Benchmarking Machine Learning Methods for Synthetic Lethality Prediction in Cancer”的研究论文。文章通过设计多个场景系统性比较了12种最新的机器学习方法在合成致死(Synthetic Lethality, SL)抗癌药物靶点预测中的表现。该研究为科学家提供了详尽的指南,帮助他们选择最适合的SL预测工具,从而推动精准抗癌药物的研发。

图1.文章标题
合成致死(SL)是一种基因之间的遗传相互作用关系,即当两个基因同时发生突变或扰动时会导致细胞死亡,而单个基因被扰动并不会产生这一效果。这一特性使SL成为一种有潜力的癌症治疗策略,因为通过靶向癌症特异性突变基因的合成致死伙伴基因,可以杀死癌细胞而不影响健康细胞的生存。尽管SL现象已经被发现超过一个世纪,但其实际应用仍然面临挑战,尤其是在快速、精准地识别与癌症相关的SL基因对(SL gene pairs)方面。
为了加速实验筛选并降低其成本,近年来,越来越多的研究人员应用机器学习技术来预测SL基因对。这些方法通过使用大量生物学数据,快速筛选出潜在的SL相互作用关系,以缩小实验验证的范围。然而,尽管已经提出了多种机器学习模型和算法,它们在不同情境下的性能缺乏系统性评估,这给研究人员在实际应用中选择合适的人工智能工具带来了困扰。
为填补这一空白,信息学院郑杰团队与合作者系统性地评估了12种最新的机器学习方法,涵盖了从传统机器学习到深度学习的多种算法。研究人员首先收集并建立了一个基准测试数据集,设计了多个不同的实验场景,包括3种数据划分方式,4种正负样本比例和3种负样本采样方法,从而评估这些模型在多种场景组合下的分类和排序候选SL基因对的能力(图2)。通过对比各种模型,研究团队发现,数据质量的提升,比如负样本的优化,对所有方法的表现均有显著提升。
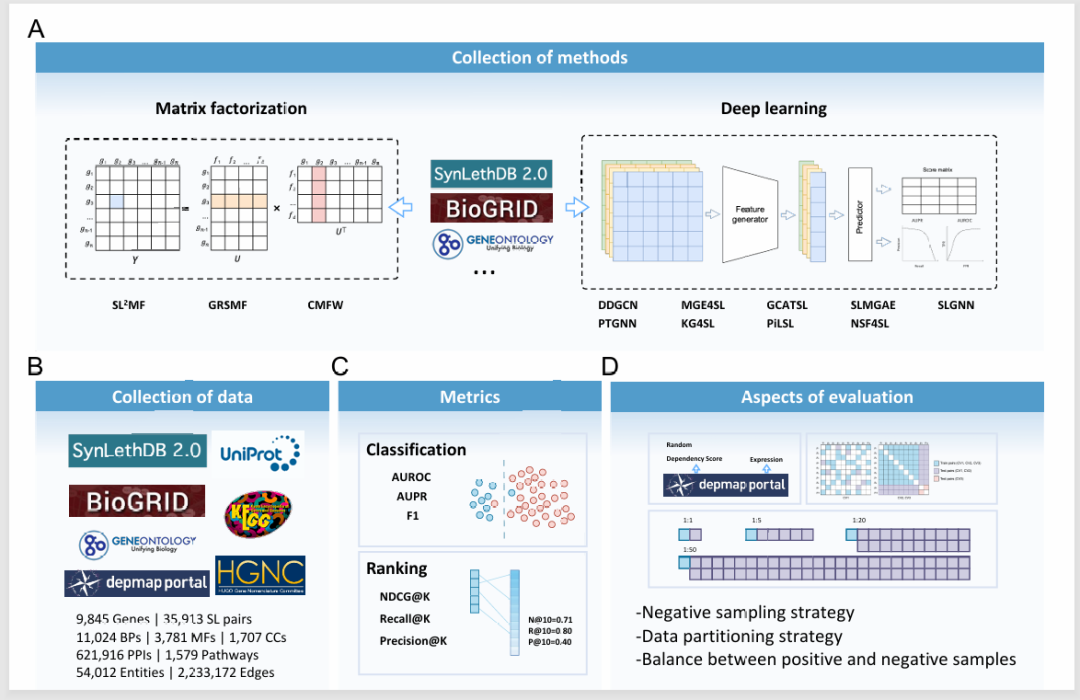
图2. 基准研究的数据集构建以及场景设计
在所有评估的方法中,SLMGAE(SL prediction with Multi-view Graph Auto-Encoder)算法表现总体最佳。然而,当在面对更加复杂的实际应用时这些方法均存在一定的局限性。特别是在“冷启动”测试中——即当模型在从未见过的新数据集上进行测试时,所有方法的表现均有所下降。此外,对于特定癌症背景下(例如细胞系特异性的SL预测任务),模型的预测准确度和泛化能力也有待进一步提升。
这些基准测试的结果不仅为科学家提供了选择SL预测方法的实用指南,还揭示了当前机器学习方法在实际应用中的瓶颈和不足。这为未来研究开发更加精准、可靠的SL基因对预测工具提供了宝贵的参考,为合成致死抗癌药物领域的研究人员提供了重要的数字资源和见解,从而有助于加速癌症靶向治疗的发展。
上海科技大学信息学院与临港实验室联合培养的2022级博士研究生冯艺苗(郑杰课题组)为该论文第一作者,新加坡科学技术研究局生物信息学研究所助理研究员龙亚辉,上海科技大学信息学院研究员李权,信息学院两位硕士研究生王鹤、欧阳阳(李权课题组)参与了本课题的研究。上海科技大学信息学院研究生毛伟帆、岳臻、陶思宇和杨扬为本工作的完成提供了帮助。上海科技大学图信中心和宁夏西云算力科技有限公司为本工作提供了算力支持。该工作最初依托于CS286 (AI for Science & Engineering)的课程项目。新加坡科学技术研究局信息通讯研究所首席科学家吴敏和上海科技大学信息学院研究员郑杰为论文共同通讯作者。上海科技大学为第一完成单位。
论文链接:
https://doi.org/10.1038/s41467-024-52900-7

 沪公网安备 31011502006855号
沪公网安备 31011502006855号