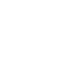上海科技大学信息科学与技术学院张海鹏课题组致力于数据挖掘的理论与应用研究,探索社交、科创、金融、人文等领域的大规模人类行为的规律、影响和机制,以支持相关领域的智能决策。近日,课题组在中国人名表征、人物行迹挖掘、有向图表征以及大语言模型泛化机制方面取得多项研究成果,正式录用、发表于国际学术会议International Conference on Machine Learning (ICML)、International Joint Conference on Artificial Intelligence (IJCAI),以及International AAAI Conference on Web and Social Media (ICWSM)。
成果一: 一种创新的中国人名拼音表征与性别预测方法
社会学、金融学以及智能营销等行为科学关注不同性别下的行为差异。许多研究通过记录中的人名来猜测性别。但是,现有的“名字-性别”猜测模型是针对西方名字设计的,对于汉语拼音名字的猜测效果并不理想,影响了相关研究的可靠性。事实上,如果将拼音关联到其可能对应的汉字,能够引入汉字所包含的性别倾向信息,来帮助判断拼音的性别倾向(图1)。课题组利用多任务学习,同时建模拼音的性别含义和拼音到汉字的模糊对应关系,为拼音赋予汉字的语义信息,并利用特征级和响应级的知识蒸馏,将汉字姓名的性别特征迁移到拼音姓名中(图2)。实验证明,提出的模型在多个姓名-性别数据集上均达到了准确的预测效果。
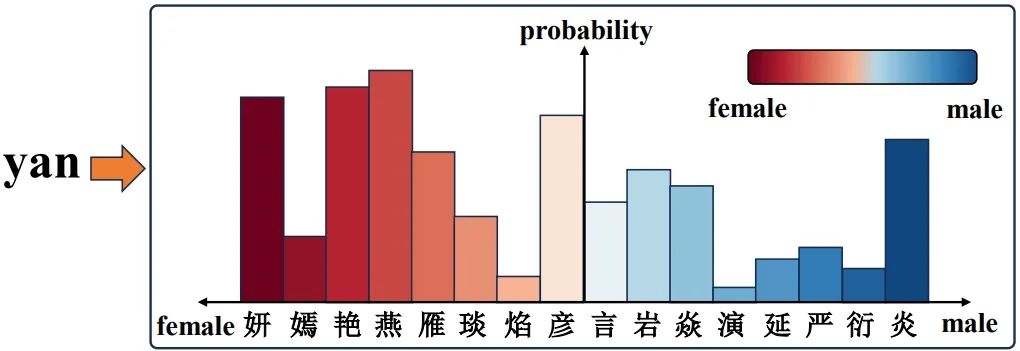
图1 拼音与汉字间对应关系及汉字性别信息示例
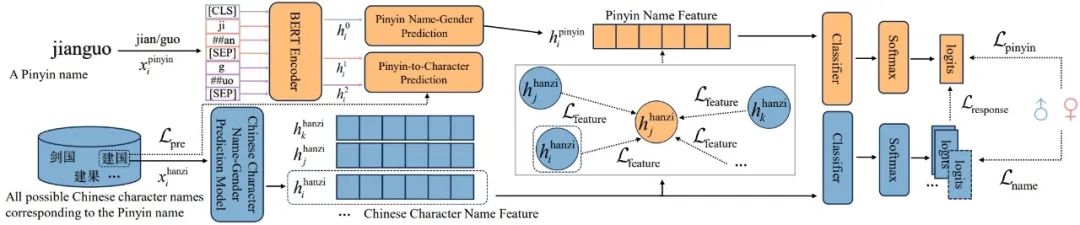
图2 模型结构
成果以题为“For the Misgendered Chinese in Gender Bias Research: Multi-Task Learning with Knowledge Distillation for Pinyin Name-Gender Prediction”发表在International Joint Conference on Artificial Intelligence(IJCAI 2024)会议上。上海科技大学是第一完成单位,信息学院2023级研究生杜晓聪为论文的第一作者,张海鹏教授为通讯作者。
论文链接:
https://arxiv.org/pdf/2405.06221
成果二: 名人的人生轨迹提取方法
名人的人生轨迹,例如何时何地出生、求学、就业、发明、创作、去世等,能够反映文化、经济、科技、教育等方面的变迁,为相关学科提供了重要的时空分析和网络科学研究视角。然而,目前可用的数据集在规模、密度和质量上都难以支撑细致化、全景式的研究。为了获得高质量、大规模的人生轨迹数据,课题组提出了两个创新性的模型,分别用于新闻和维基百科的人物人生轨迹提取。
——新闻报道中的名人轨迹检测
新闻报道中包含许多名人轨迹,但其中也存在大量噪声:新闻中包含许多与轨迹的无关信息;对于一条轨迹信息,其关键元素往往散落在不同的新闻中;部分轨迹描述使用代称进行间接的隐式表达。这给提取轨迹带来了挑战。课题组提出了一个基于图神经网络的名人轨迹检测模型CeleTrip(图3):通过将文档建模为图结构,聚合来自不同新闻文章的语义信息,采用基于注意力机制的图池化过滤无关信息,并引入外部知识来补充隐含的行程信息。实验结果表明,CeleTrip能够准确地从新闻中提取名人轨迹。
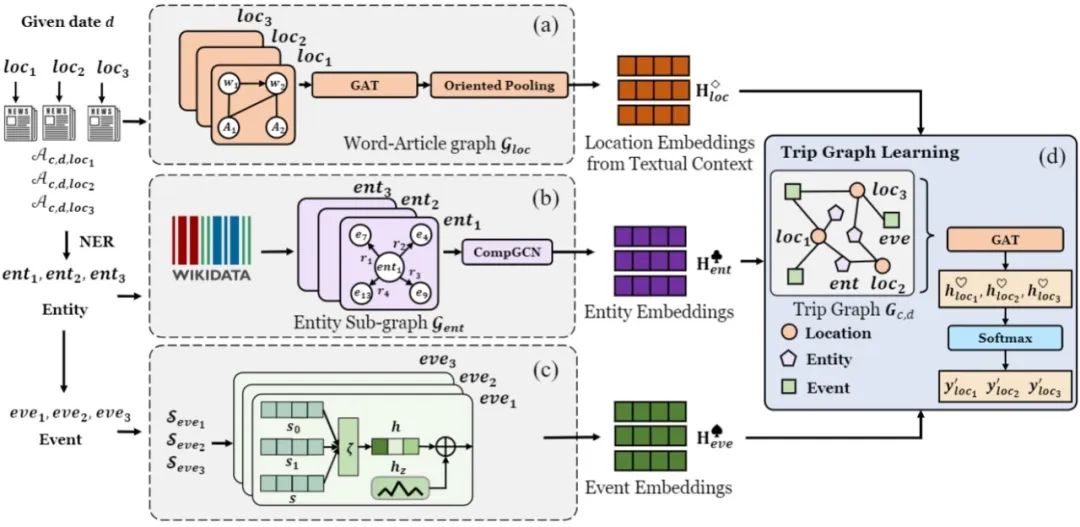
图3 CeleTrip 框架图
相关成果以题为“Where Did the President Visit Last Week? Detecting Celebrity Trips from News Articles”发表在International AAAI Conference on Web and Social Media(ICWSM 2024)会议上,并入选Spotlight Paper (投稿论文前5%)。上海科技大学是第一完成单位,信息学院2020级研究生彭凯、2022级研究生章颖为论文的共同第一作者,张海鹏教授为通讯作者。
论文链接:
https://ojs.aaai.org/index.php/ICWSM/article/view/31382/33542
——维基百科百万级人物轨迹提取
维基百科中包含大量名人的人生轨迹信息,相较新闻报道中的人生轨迹,其类型十分丰富,描述行迹的上下文信息也纷繁复杂,而训练数据仅能覆盖一小部分轨迹种类。因此,为了精确提取轨迹并保证覆盖率,模型需要具备很好的泛化能力。课题组提出结合对比学习和半监督学习思想的集成模型COSMOS(图4),通过发现输入样本之间的联系和差异,增强模型对输入数据的理解,提高其泛化能力;同时,利用少量标注数据和大量无标注数据,帮助模型学习到更广泛的知识表征,从而在新的分布上也能保持良好的性能。COSMOS模型在测试数据集上超越基线模型,达到了优良的提取效果。目前团队已构建了包含500万条数据的名人轨迹数据集,以支撑相关研究。
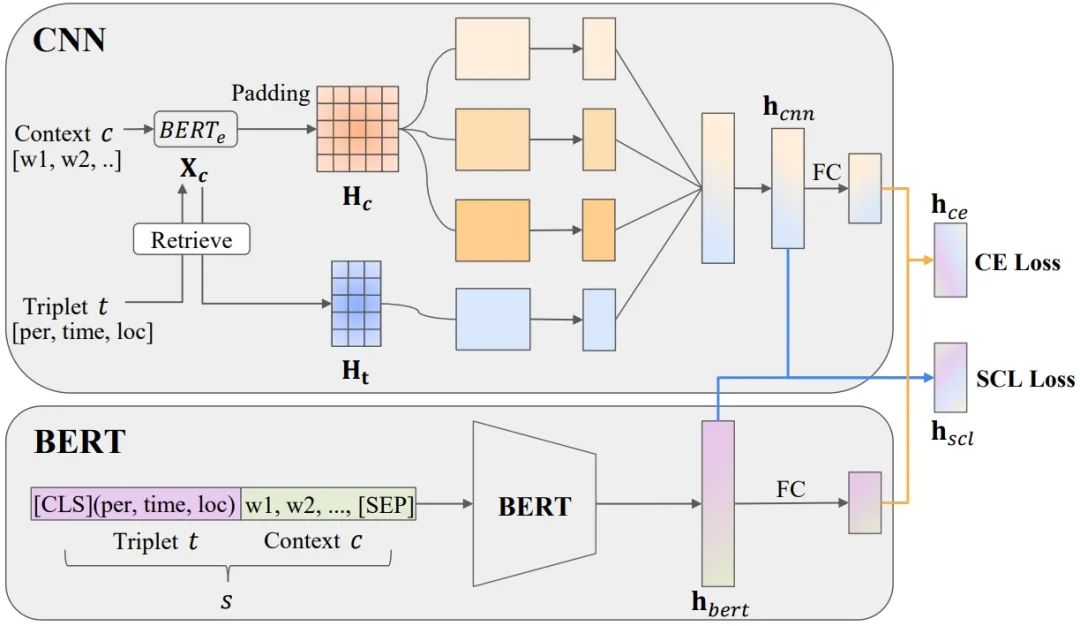
图4 COSMOS框架图
相关成果“Paths of A Million People: Extracting Life Trajectories from Wikipedia”已被International AAAI Conference on Web and Social Media(ICWSM2025)会议正式接收。上海科技大学是第一完成单位,信息学院2022级研究生章颖、李笑风为论文的共同第一作者,张海鹏教授为通讯作者。
论文链接:
https://arxiv.org/pdf/2406.00032
成果三: 一种基于双图注意力网络的自监督有向图复嵌入方法
有向图广泛应用于带有方向信息的关联数据建模,包括金融网络、社交网络、交通网络、引文网络等。当前的有向图表征方法建立在无向图嵌入的基础上,普遍存在以下问题:未充分利用邻居信息,导致对低出、入度节点的表示能力较弱;对于表示训练阶段未出现节点的归纳学习能力有限;训练过程与具体下游任务过度耦合,影响节点嵌入的跨任务泛化性。为解决这些问题,课题组提出一种基于双图注意力网络的自监督有向图复嵌入方法DUPLEX(图5)。它利用厄米邻接矩阵分解原理,充分利用邻居信息;引入双图注意力网络编码器,进行有向邻居聚合;引入两个无参解码器,将训练过程与特定下游任务解耦。实验结果证明,DUPLEX优于基线模型,在各种任务中展示了良好的归纳能力和适应性,尤其对于稀疏连接图,有较强的表征能力。
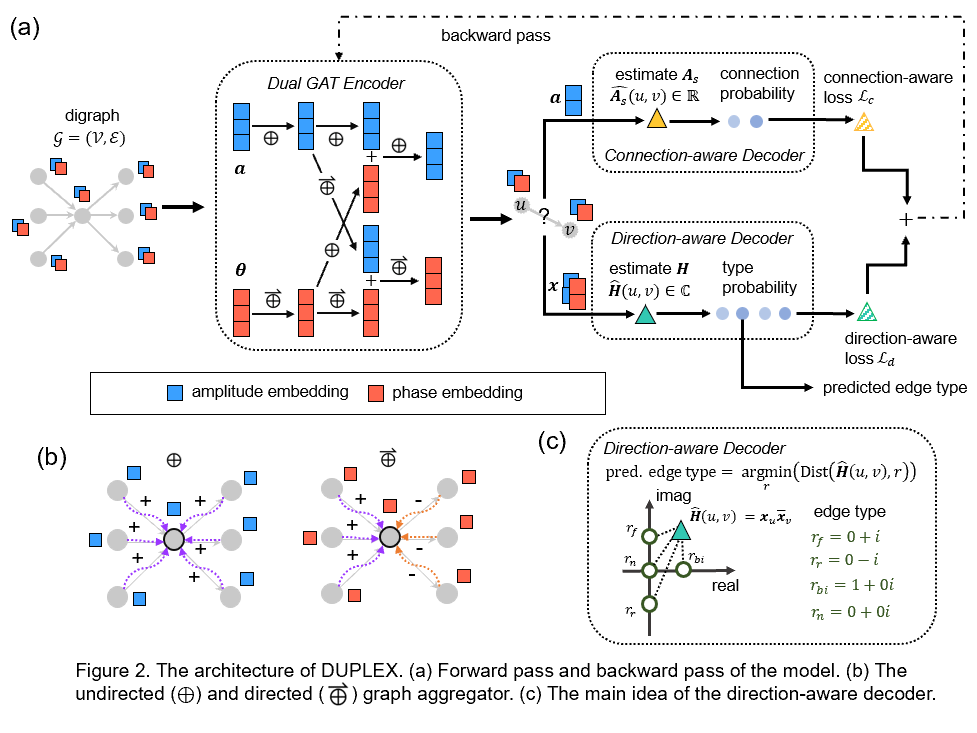
图5 DUPLEX框架图
相关成果以题为“DUPLEX: Dual GAT for Complex Embedding of Directed Graphs”发表在International Conference on Machine Learning(ICML 2024)上。信息学院2021级研究生柯昭如为论文的共同第一作者,张海鹏教授为共同通讯作者。
论文链接:
https://icml.cc/virtual/2024/poster/34257
成果四: 大语言模型分布外泛化机制研究
大语言模型在许多不同类型的问题上表现出色,但其泛化能力仍明显不足。这样的问题在训练数据分布外(Out-of-Distribution,OOD)的泛化任务上尤为显著,即模型在与训练数据明显不同的数据分布上进行推理和预测的能力较弱,而OOD泛化效果下降的背后机制尚不明确。课题组针对这一问题,研究聚焦于n位数加法和乘法等数学任务,观察生成式模型在训练时能否成功泛化至未见过的更长输入(OOD泛化),来揭示其泛化效果下降的机制。研究发现,在训练数据分布内(In-Distribution, ID)泛化时表现优异;尽管在处理未见过的OOD输入时表现不佳,模型并非没有学到有意义的信息,而是学习到了清晰的代数结构。这些发现加深了对包括大语言模型在内的生成模型泛化能力的理解。
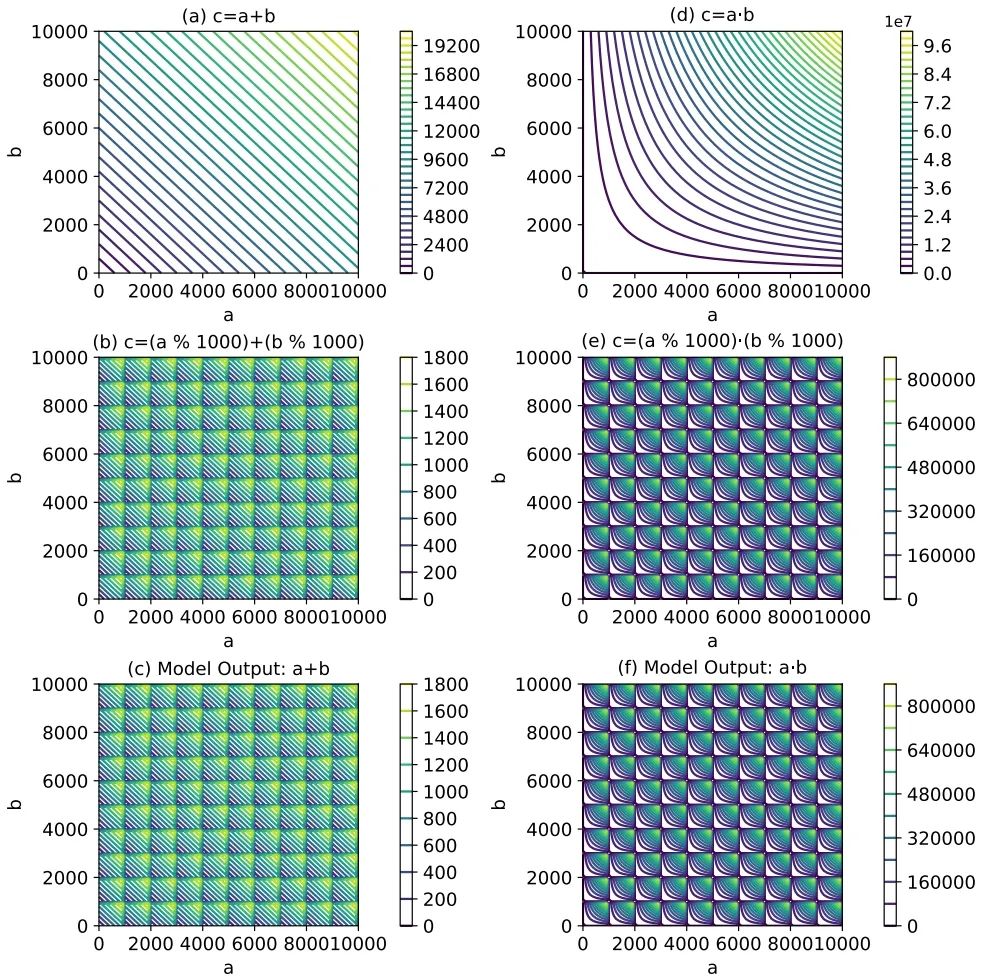
图6 模型在加法与乘法运算中的泛化结果与等价关系
相关成果以题为“It Ain’t That Bad: Understanding the Mysterious Performance Drop in OOD Generalization for Generative Transformer Models”发表在International Joint Conference on Artificial Intelligence(IJCAI 2024)上。信息学院2021级研究生潘子豪为论文的共同第一作者,张海鹏教授为共同通讯作者。
论文链接:
https://www.ijcai.org/proceedings/2024/0727.pdf

 沪公网安备 31011502006855号
沪公网安备 31011502006855号