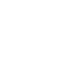智能感知与人机协同教育部重点实验室依托上科大信息科学与技术学院,探索下一代人类智能与机器智能的协同发展和相互增强,建立人类智能与机器智能交互协作的新型理论基础和实验平台。自筹建以来,实验室通过结合多个模态的高精度数据建模,开始建立感知算法、常识推理和决策规划的软硬件统一框架,用以实现人类智能与机器智能的协同合作与演化。
近日,实验室团队在计算机视觉领域国际知名会议International Conference on Computer Vision(ICCV 2023)上发表多篇论文,涵盖三维/动态场景感知与建模,负责与可持续机器学习理论,复杂场景下多智能体交互,以及智能芯片与感知系统等四个主要研究方向,展示了实验室在开放世界视觉理解、视觉-语言基础模型、事件相机的几何视觉理论、三维场景理解、零次学习等多方面的学术成果,为实现智能人机交互新范式打下了坚实的基础。
I. 三维/动态场景感知与建模
针对复杂的交互环境,实验室团队发展了两方面基于多模态感知的信息获取方法,进行全方位的细粒度感知理解,并建立精准的模型和相关知识表征。
以人为主的三维场景理解/Human-centric Scene Understanding in 3D Large-scale Scenarios
研究提出了一个大规模多模态(激光雷达-相机)数据集HuCenLife,收集了大量室内、室外的日常生活场景数据,并提供了细粒度的标注。该数据集可以帮助许多3D感知任务,如分割,检测,动作识别和预测等,可以促进服务型机器人、自动驾驶、人机交互等应用的发展。研究工作还为这些任务提供了基准模型,达到了当前最优的性能,代码和数据集已公开,以促进相关研究。
文章的共同第一作者是上科大信息学院2019级本科生、现2023级研究生许艺腾;2021级硕士研究生丛培珊;2019级本科生、现2023级研究生姚奕忱。通讯作者是马月昕助理教授。详情见项目主页:https://github.com/4DVLab/HuCenLife.git
基于多模态视觉数据的零次点云分割/ See More and Know More: Zero-shot Point Cloud Segmentation via Multi-modal Visual Data
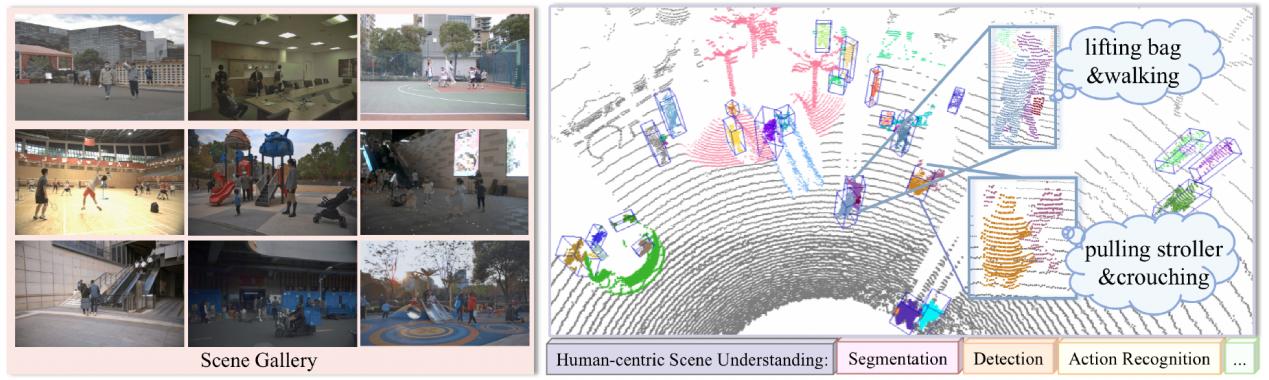
研究人员提出了一种新的多模态零样本学习方法,通过利用点云和图像的互补信息和语义-视觉特征的互相增强,实现更精确的视觉语义对齐,使模型能够分割出训练阶段看不到的点云中的新物体。该方法在两大公开数据集SemanticKITTI和InuScenes上进行了充分的实验,均达到了最优的性能。
论文的共同第一作者是上科大信息学院科研助理陆宇航与2022级研究生姜奇,通讯作者是马月昕助理教授。详情见项目主页:https://github.com/4DVLab/See_More_Know_More.git
2. 负责任与可持续机器学习理论
在人-物-环境的精准感知基础上,实验室团队不断探索人机协同中的学习理论框架,发展了包括模糊多样的人类知识获取与基于大模型的可持续人机交互基础两方面的工作。
基于类间关系知识蒸馏的新类别发现/ Class-relation Knowledge Distillation for Novel Class Discovery
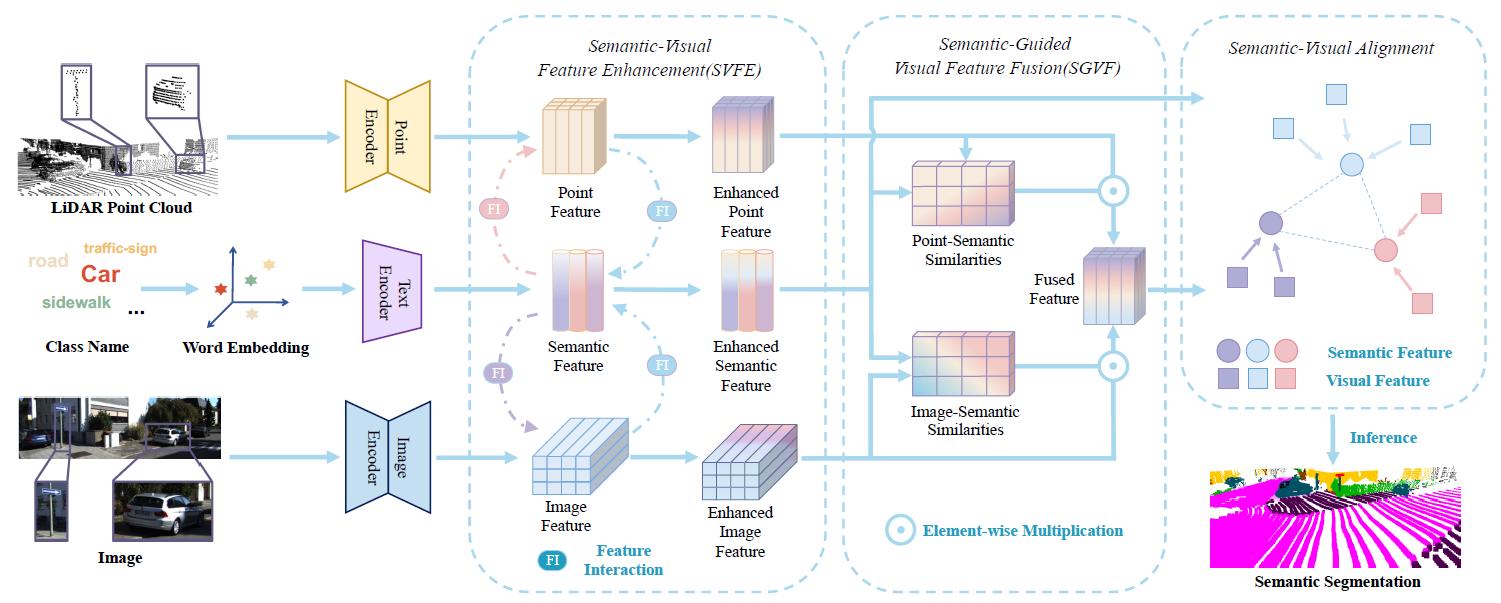
目前的深度学习模型通常在封闭世界中解决问题,但真实世界是一个开放世界,人类在面对真实世界中遇到的新问题时通常会运用过往的知识去解决它。目前大多数解决方案都是通过简单地共享特征空间来传递知识,无法充分利用已知类数据的知识。针对此挑战,研究人员提出了一种新颖的知识蒸馏框架,它利用已知类模型提供的类关系表示来引导新类的学习,自适应地促进知识转移。通过在多个基准数据集上的大量实验表明,该框架几乎在所有基准数据集上均显著优于以往的最先进方法。
论文的共同第一作者是上科大信息学院与临港实验室联合培养的2020级博士生张楚瑜和信息学院2019级本科生顾培炎,通讯作者是何旭明副教授。2022级硕士生徐睿洁等也参与了合作。
视觉-语言模型的视觉提示词?合成文本图像!/ LoGoPrompt: Synthetic Text Images Can Be Good Visual Prompts for Vision-Language Models
如何利用大规模预训练视觉-语言模型一直是视觉-语言领域研究中棘手的问题,之前的主流方法主要研究如何从可学习的Text Prompt在少样本任务下取得性能提升,缺乏视觉分支的研究。研究人员发现合成的文本图像具有激活大规模预训练视觉-语言模型的视觉感知能力,并提出了一种新颖的视觉提示词方法,在10多个下游数据集和不同的任务设定中均显著超越之前方法。审稿人一致认为该策略极具创新性和启发性。

论文的第一作者是上科大信息学院杨思蓓课题组2022级研究生石骋,通讯作者是杨思蓓助理教授。详情见项目主页:https://chengshiest.github.io/logo/
浅层密集对齐助力开放词汇目标检测/ EdaDet: Open-Vocabulary Object Detection Using Early Dense Alignment
视觉语言模型(如CLIP)提升了开放词汇的目标检测性能,现有方法利用CLIP的强大零样本识别能力,将目标级别的嵌入与类别的文本嵌入进行对齐。然而,使用CLIP进行目标级别对齐会导致对基本类别过拟合,即与基本类别相似的新类别无法被正确识别,却被识别为相似的基本类别。为了解决这个问题,研究人员首先确定关键细粒度图像语义的损失阻碍了现有方法实现强大的基本类别到新类别的泛化。继而提出了Early Dense Alignment (EDA)来弥合可泛化局部语义和目标级别预测之间的差距,大幅提高之前方法,取得开放词汇物体检测最优的性能。
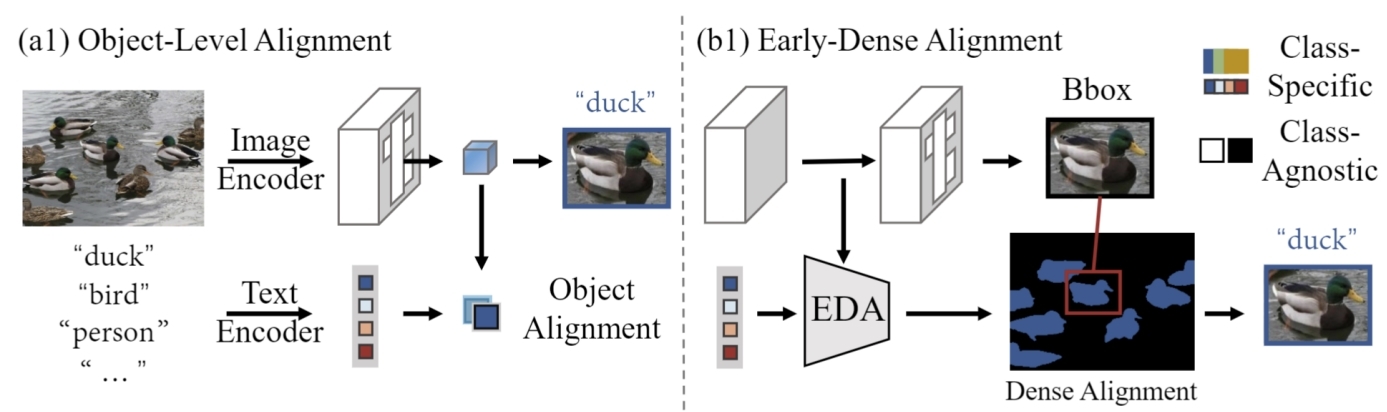
论文的第一作者是上科大信息学院杨思蓓课题组2022级硕士生石骋,通讯作者是杨思蓓助理教授。详情见项目主页:https://chengshiest.github.io/edadet/
大语言模型可供性知识引导的目标检测/ CoTDet: Affordance Knowledge Prompting for Task Driven Object Detection
以GPT-3.5 和ChatGPT为代表的大语言模型(LLM)展现了在编码来自大量文本数据的通用世界知识方面的能力,但LLM对处理与现实场景相关的视觉-语言任务存在着瓶颈。为了解决这个问题,团队提出了视觉可供性概念和利用多级思维链(CoT)提示从LLM显示提取可供性知识的新方法,并利用这些知识来连接目标检测和现实场景需求。该成果在性能上显著超过了现有方法,并有更好的泛化性和一定的可解释性。

论文共同第一作者是上科大信息学院杨思蓓课题组2023级博士研究生唐嘉晋与2019级本科生(现2023级研究生)郑舸,通讯作者是杨思蓓助理教授。详情见项目主页:https://toneyaya.github.io/cotdet/
3. 复杂场景下多智能体交互
实验室在基于精准感知与人机协同学习理论基础上,开发了一系列方法来实现人机多智能体在复杂应用场景中的交互。
具有失配关系推理的图像文本匹配与定位/ Grounded Image Text Matching with Mismatched Relation Reasoning
研究人员提出了一项名为“具有失配关系的图像文本匹配与定位(GITM-MR)”的全新视觉语言联合任务,展示了基于Transformer预训练模型对物体间关系的理解能力在数据效率和句子长度泛化能力方面存在不足。研究进一步提出了“关系敏感的对应推理网络(RCRN)”,显著提升了原模型的性能。该研究对于推动预训练模型在图像文本匹配任务中的发展,以及改进模型在关系理解能力、数据效率和句子长度泛化方面的表现具有重要的意义。
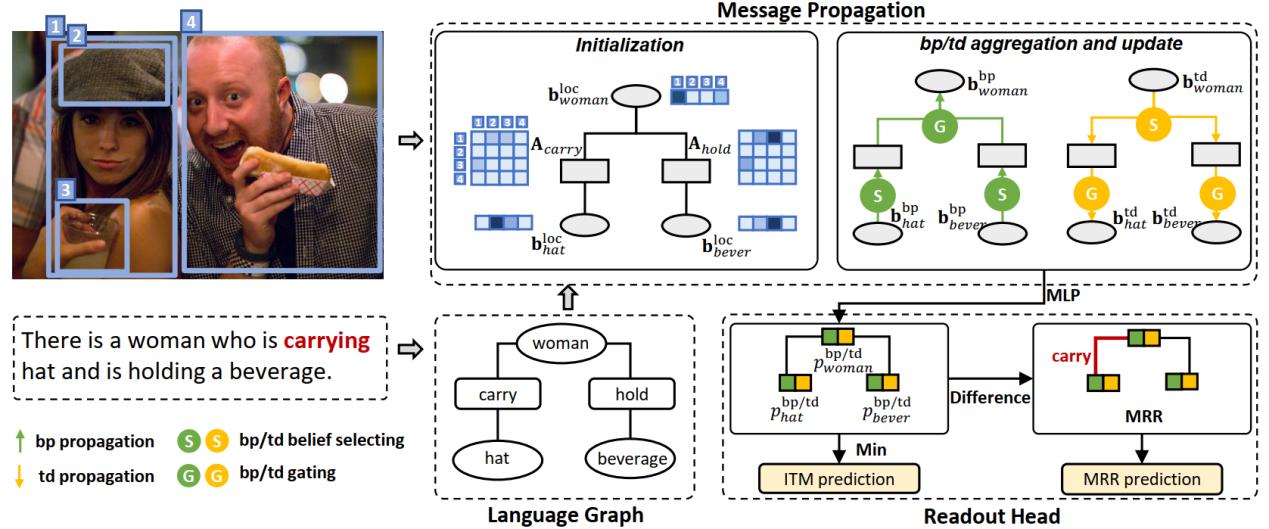
论文共同第一作者是上科大信息科学与技术学院2021级硕士生吴隅和魏雅娜,通讯作者是何旭明副教授。2020级硕士生王浩哲(现就职于阿里巴巴)、2017级博士生刘永飞(现就职于字节跳动)、杨思蓓助理教授等也共同合作参与了项目。
基于时序收集与分发的指代式视频物体分割/ Temporal Collection and Distribution for Referring Video Object Segmentation
指代式视频物体分割是视觉与语言理解领域的重要挑战。尽管以DETR为基础的分割框架在视频物体分割领域已取得显著成果,但在捕捉物体的运动变化和实现有效物体跟踪方面仍存在着重大限制。研究团队提出了解决该任务时序问题的新范式:通过同时维护局部物体查询和全局指代标记实现物体级别时序信息的建模和交互。全局指代标记根据语言表达捕获视频级别的指代信息,而局部物体查询在每一帧中定位和分割物体。该模型在所有基准测试中始终显著优于现有的最先进方法。
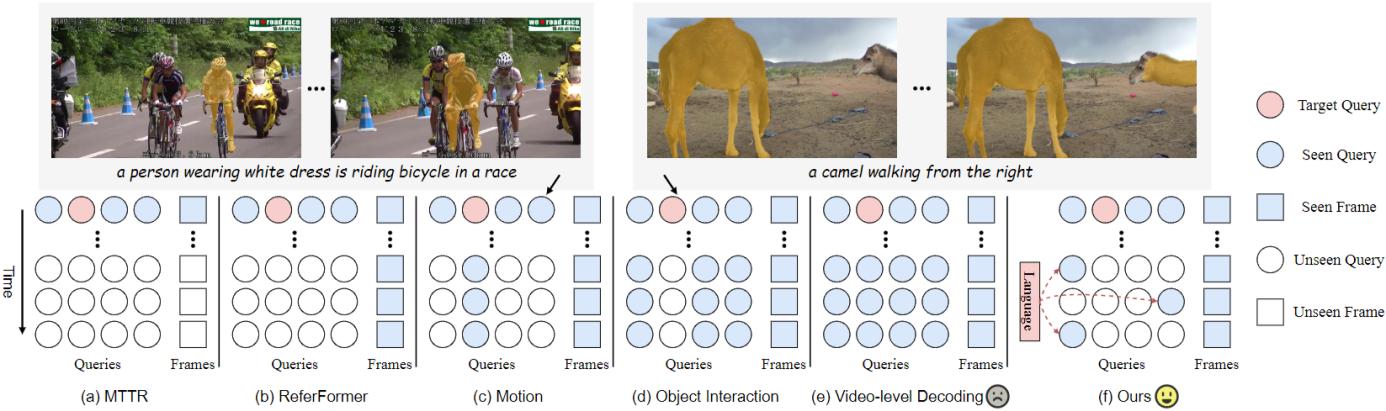
论文第一作者是上海科技大学信息学院杨思蓓课题组2023级博士研究生唐嘉晋,通讯作者是杨思蓓助理教授。2023级学生郑舸共同参与合作。详情见项目主页:https://toneyaya.github.io/tempcd/
4. 智能芯片与感知系统
此外,实验室在不断推进基于新一代集成电路与感知计算的高效能比平台,发展多智能体协同系统的低能耗和可持续性。
基于事件相机相对运动估计的五点最小求解器/A 5-Point Minimal Solver for Event Camera Relative Motion Estimation
研究人员成功地通过精确的非线性流形表征解决了事件相机中的运动估计问题。通过这种参数化方式,他们提出了一个新颖的最小五点求解器,可以估计线参数和相机速度投影,并可以将多个估计结果融合成单一的平均速度。通过模拟和真实数据上证明,该方法在估计线速度时成功率高达100%,远超过现有闭式求解器的23%-70%。
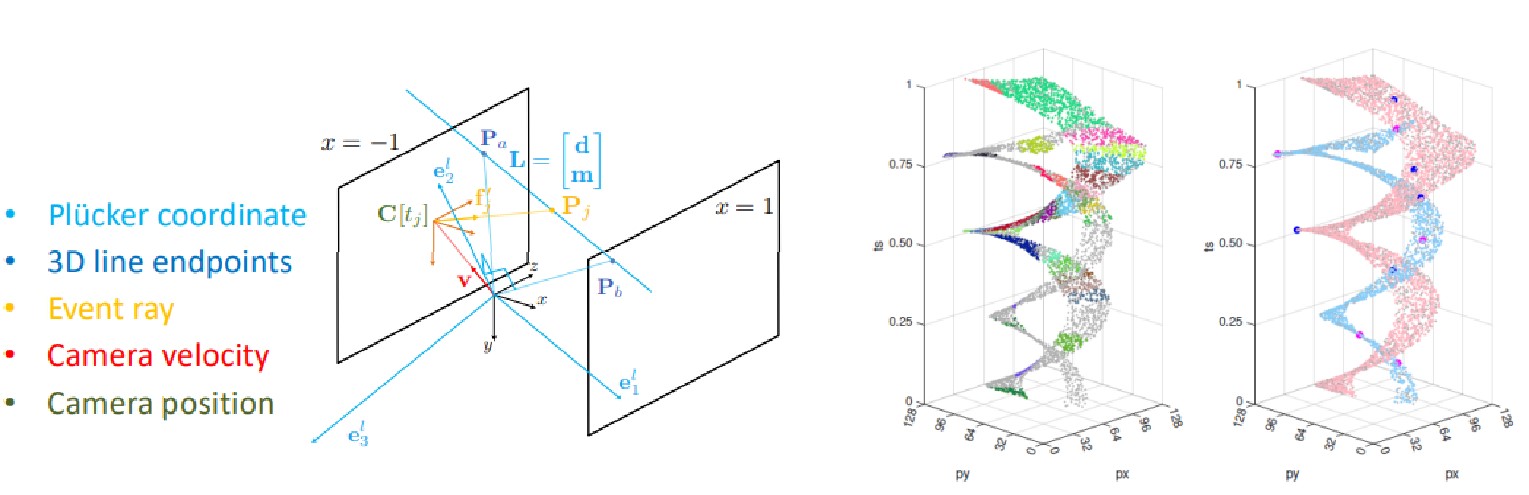
文章的共同第一作者是上科大信息学院2021级博士生高翎和2023级博士生苏杭。通讯作者是Laurent Kneip教授。苏黎世大学的Daniel Gehrig,Marco Cannici和Davide Scaramuzza教授也共同参与合作。
文章链接:https://arxiv.org/abs/2309.17054
项目主页:https://mgaoling.github.io/eventail/

 沪公网安备 31011502006855号
沪公网安备 31011502006855号