近几年,随着人工智能的创新成果与经济社会各领域的深度融合,人工智能已逐渐成为赋能实体经济高质量发展的新动能,作为传统产业改造升级的“助推器”影响着人们的生产与生活方式。今年刚过去4个月,我院视觉与数据智能中心就有29篇论文被国际顶尖会议接收,论文主题覆盖了包括计算机视觉、机器学习、自然语言处理、计算机图形学以及多智能体系统的研究热点,致力于解决包括数字娱乐、建筑设计、交通监控和控制、医学成像以及数字经济等生活中的各类问题。

信息学院视觉与数据智能中心成员合影
计算机视觉技术的发展,就好比人工智能不断进化的双眼,为无人驾驶载具这个热门领域奠定了坚实的基础。Laurent课题组针对车载环视相机系统的优化以及车辆位姿估计方法的优化进行了研究,提出了相应的算法及优化策略,并在特定的场景下验证了其有效性。为了解决多视图几何中的鲁棒模型拟合问题,Manolis课题组和Laurent课题组提出了使用对偶主成分分析(DPCP)的方法作为随机采样一致(RANSAC)方法的有效替代,在真实数据上的实验证明了该方法在确保高水平的拟合性能的同时,将运行时间缩短了一个数量级。为了解决“无对应点线性回归”问题,Manolis课题组尝试用代数几何的方法,通过线性回归拟合给定数据集来应对样本和观测量之间的未知的对应关系。以上研究多篇论文被国际计算机视觉与模式识别会议(CVPR)、IEEE机器人与自动化国际会议(ICRA)所接收。
随着深度神经网络技术的快速发展,人工智能正被广泛应用于医学影像分析。通过引入人工智能算法提高对医学影像分析的精度,可以为疾病的准确诊断和有效治疗提供必要支持。为了提高疾病分类和筛查的图像可视性,高盛华课题组提出了无监督的感知辅助对抗适应网络来对不同域的光学相干断层扫描(OCT)图像进行脉络膜分割,该方法在源域和目标域上都取得了很好的效果,消除了域差异对脉络膜分割性能的影响;提出一种创新的基于数据生成来解决开集(Open-set)问题的模型;采用神经网络自编码器对已知类别分布进行建模,并在已知类别分布边缘采样生成数据的策略;提出了一种新的异常检测框架(即,稀疏约束的生成对抗网络,Sparse-GAN),可以在只有健康数据的情况训练出一个用于疾病筛查的模型;提出一种用于多任务学习的特征分离和联合网络来同时诊断糖尿病性视网膜病变和糖尿病性黄斑水肿。以上论文成果极大地节省了时间、精力、成本,减轻临床医生的负担。文章被IEEE生物医学成像国际会议(ISBI)所接收。
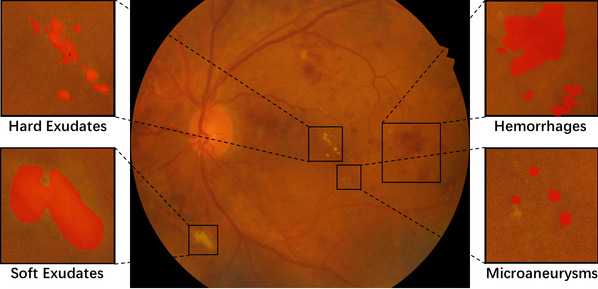
糖尿病性视网膜病变和糖尿病性黄斑水肿的眼底彩色图
计算机视觉不仅在交通以及医学领域发挥着重要的作用,在建筑设计、安全监视以及数字娱乐方面的发展也不容小觑。为了让计算机视觉拥有像人类眼睛一样的三维感知,计算机视觉正在“识别”的基础上,走向 “三维重建”。高盛华课题组从建模的效率、建模的结构等方面不断地做尝试。他们针对多视角立体重建任务进行研究,提出了一种从稀疏到稠密的重建框架,提高了重建的效率。为了解决360°图片中室内场景下的深度估计问题,提出了一种基于几何结构的模型;为了预测目标行人的运动轨迹,提出了一种新颖的用于行人轨迹预测的高阶图卷积网络(GCN)结合GCN进行高阶交互式建模。虞晶怡课题组主要采用渲染方法来实现自由视角下三维人物的高质量重建与渲染。他们提出了一种端到端的动态人物渲染方法(NHR),可重打光神经渲染方法,分别实现了自由视角下的三维人物视频效果以及基于单光照多视角图片作为输入的视角合成和重打光。他们还提出针对人脸的自标定近光源彩色光度立体重建方法,利用3D可变形模型提供的人脸几何先验进行近点光源的自标定,同时结合了人脸反照率分布特性提高重建精度。以上论文被CVPR以及IEEE计算摄影学国际会议(ICCP)所接收。

可重打光神经渲染的网络框架
除了计算机视觉以外,还有许多研究人员致力于探索人工智能在多智能体系统决策方面的强大能力。为了在少样本情况下主动探索任务,何旭明课题组提出了一种元强化学习的新颖策略,设计了一个基于图神经网络的任务推断机制,可以对新任务进行快速适应。赵登吉课题组则率先尝试将传统算法博弈论的研究与社交网络相结合,利用社交关系驱动解决全球数字经济环境下的新挑战,从科学的角度提出创新模型,以服务中国快速发展的数字经济。他们解决基于社交网络的广告、资源分配、任务众包等数字经济新模型下的反欺诈设计,包括利用社交网络进行更有效的资源分配/商品销售,在有限资源的限制下将内容通过社交网络分享给更多人,或者通过社交网络结合众包机制有效获取一个任务的答案。以上科研成果被国际人工智能会议(IJCAI)、智能体及多智能体系统国际会议(AAMAS)和欧洲人工智能会议(ECAI)所接收。
自然语言处理研究如何让计算机自动理解和生成人类语言,是人工智能领域的主要方向之一。屠可伟课题组着重研究语言内在结构(诸如词性序列、句法、语义)的自动学习,特别是在缺少人工标注的低资源场景下的无监督和半监督学习。他们提出了一种基于条件随机场自编码器的模型,通过从句子预测语义依存结构、再试图从这种结构重建句子的学习方式,半监督地学习语义依存分析器。同时,他们针对近期较为热门的无监督成分句法分析方向,提出了规范化的实验设定,并据此比较了多个传统方法和深度学习方法,发现深度学习方法相对于传统方法并无明显优势。此外,他们与阿里巴巴达摩院合作提出了结构层级的知识蒸馏技术,用于学习可以同时处理多门语言的序列标注模型。最后,在语言生成方向,他们与加州大学洛杉矶分校的合作者对开放领域对话生成的自动评价进行了深入研究。以上多篇论文被国际计算语言学协会年会(ACL)所接收。何旭明课题组为了进一步消除视觉定位中的歧义问题,设计了一个跨模态图匹配策略来解决多短语下的视觉定位任务,包含了language- context graph以及 visual-context graph两个主要的模块。该论文被AAAI(美国人工智能年会)所接收。
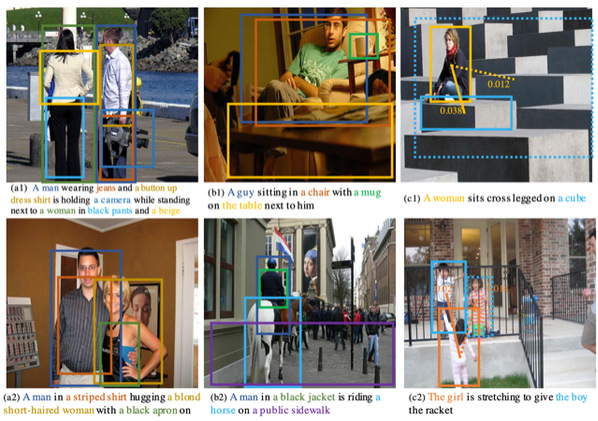
视觉定位定性结果
信息学院视觉与数据智能中心致力于建立新一代人工智能体的基础理论和应用探索。中心在理论研究上将大力推动感知模块、学习算法、常识推理和仿真模拟的结合,突破单个AI领域的局限,从感知到决策的各个层面提出新的智能体理论框架;深入探索机器智能与人类智能的协同发展和相互增强,建立人类与机器智能的交互合作的理论基础和实验平台;在此基础上,建立跨学科人工智能的应用基础,通过结合基础科学,设计管理和艺术创造等方面对人工智能的应用场景进行大范围地扩展,促进上述学科在人工智能方法协助下实现创新性理论的快速迭代和发展。

 沪公网安备 31011502006855号
沪公网安备 31011502006855号