

Professor Xuming He's research group has made important progress in the fields of computer vision and machine learning.Four papers are accepted by IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2021).CVPR is an annual IEEE international academic conference and one of the three top academic conferences in the field of computer vision. It enjoys a high reputation in the world. According to the statistics of Google Scholar Metrics as of June last year, CVPR ranks fifth in the comprehensive influence of all publications and conferences included by Google
Scene graph generation is an important visual understanding task with a broad range of vision applications. The visual relationships compose of the instances and the interaction between them, which can be represented as triplets formally (subject entities, predicate, object entities). The multiple visual relationships of images can be constructed as a scene graph by linking the entities by relationships.
Such structural high-level visual information can provide a foundation for downstream visual reasoning tasks such as VQA, and image retrieves, etc.
Despite recent tremendous progress, it remains challenging due to the intrinsic long-tailed class distribution and large intra-class variation. To address these issues, we introduce a novel confidence-aware bipartite graph neural network with an adaptive message propagation mechanism with the perspective of the sparsity of semantic constraint in the scene graphs.To this end, our proposed method is able to model the context more effectively for unbiased scene graph generation.
In addition, we propose an efficient bi-level data resampling strategy to alleviate the imbalanced data distribution problem in training our graph network. Comparing with the previous methods, the bi-level resampling strategy achieves a more optimal performance trade-off between the high-frequency and low-frequency categories.Our approach achieves superior or competitive performance over previous methods on several challenging datasets, including Visual Genome, Open Images V4/V6, demonstrating its effectiveness and generality.
The first author of this work is SIST MS student LiRongjie, and Dr. Xuming He is the corresponding author. This research work was supported by Shanghai NSF Grant and ShanghaiTech start-up funding. Link to this article:https://arxiv.org/abs/2104.00308
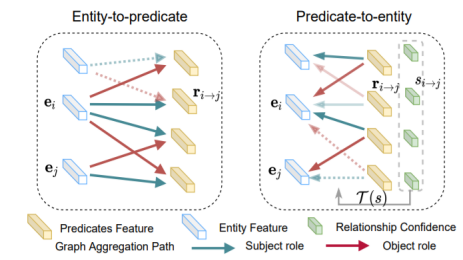
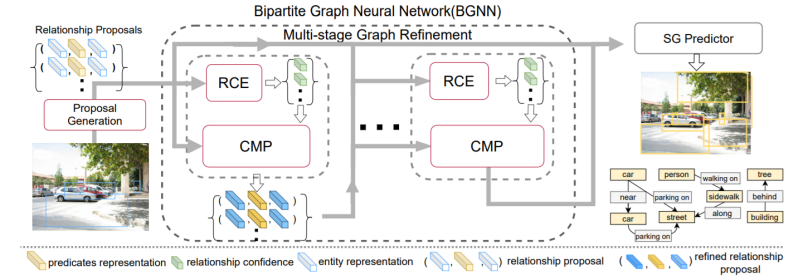
Fig. The left part of figure shows the algorithm pipeline and model architectural, the right part shows the insight of the novel confidence-aware bipartite graph neural network with an adaptive message propagation mechanism.
Cross-modal understanding of visual scene and natural language description plays a crucial role in bridging human and machine intelligence, and has attracted much interest from AI community. Towards this goal, the core problem is to establish instance-level correspondence between visual regions and its related language entities, which is commonly referred to as visual grounding. Such correspondence serves as a fundamental building-block for many vision-language tasks, such as image captioning, visual question answering, visual navigation and visual dialog. Previous methods always suffer from the visual and matching ambiguity from several aspects. 1.) Fixed precomputed object proposal set that contain many distractor or background regions, making it difficult to infer positive matches for learning. 2.) These proposals are typically kept fixed during learning, which leads to inaccurate localization bounded by the external detectors. Xuming He’s group proposed a novel context-aware weakly-supervised learning method that incorporates coarse-to-fine object refinement and entity relation modeling into a two-stage deep network, capable of producing more accurate object representation and matching. To effectively train their network, two novel loss functions are designed, which is self-taught regression loss and relations classification loss. Those loss can enable network to learn a better localization and strong context dependency.
The first author of this work is SIST PhD student Liu Yongfeiand MS student WanBo, both author contributes equally. Dr. Xuming He is the corresponding author. This research work was supported by Shanghai NSF Grant and ShanghaiTech start-up funding.
This work is also collaborated with Meituan senior research Dr. MaLin
Link to this article:https://arxiv.org/pdf/2103.12989.pdf
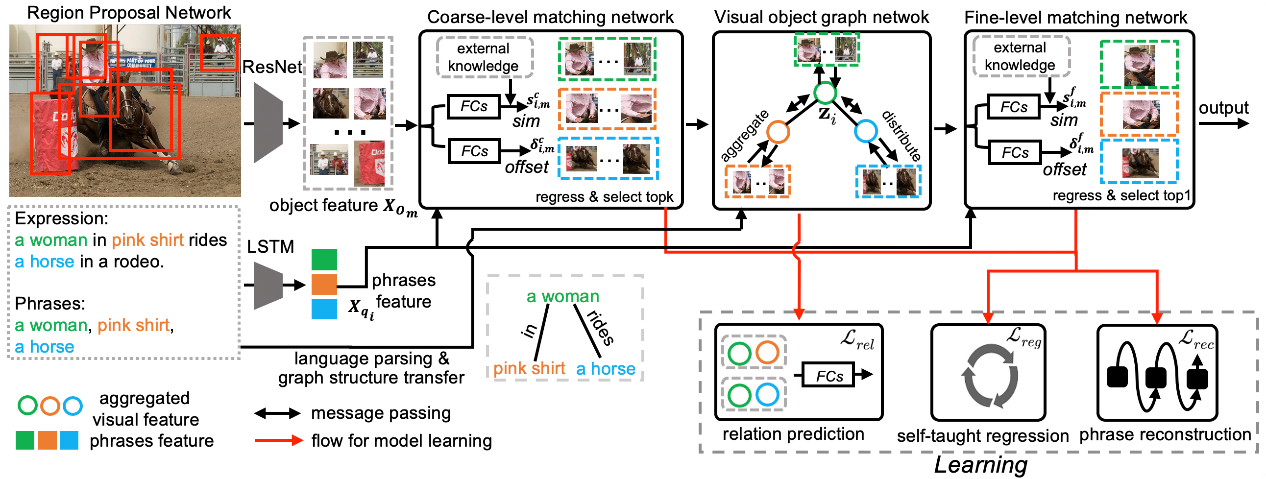
Fig. Model Overview
The authors address the problem of class incremental learning, which requires the model continuously to learn novel concepts without forgetting old concepts. It is also a core step towards achieving adaptive vision intelligence. In particular, the authors consider the task setting of incremental learning with limited memory and aim to achieving better stability-plasticity trade-off. To this end, the authors propose a novel two-stage learning approach that utilizes a dynamically expandable representation for more effective incremental concept modeling. The authors conduct extensive experiments on the three commonly used class incremental learning benchmarks including CIFAR-100, ImageNet-100, and ImageNet-1000. Moreover, for each benchmark, they evaluate the methods with two popular protocols including starting with a pretrained model or without a pretrained model. The empirical results demonstrate the superiority of our method over prior state-of-the-art approaches with comparable or less parameters. Interestingly, the authors find that their method can even achieve positive backward and forward transfer between incremental steps.
The first authors of this work are SIST PhD student Yan Shipeng, and MS student Xie Jiangwei(Equally contributed). Dr. Xuming He is the corresponding author. Link to this article:https://arxiv.org/abs/2103.16788
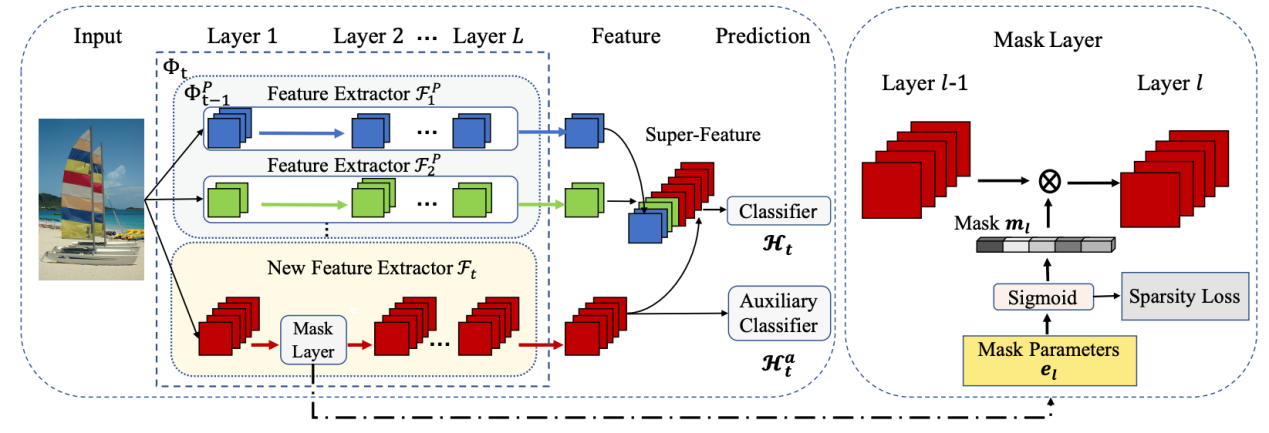
Fig. Dynamically Expandable Representation Learning. At step t, the model is composed of super-feature extractor and classifier, where the super-feature extractor is built by expanding the existing super-feature extractor with new feature extractor. We also use an auxiliary classifier to regularize the model. Besides, the layer-wise channel-level mask is jointed learned with the representation, which is used to prune the network after the learning of model.
Despite the recent success of deep neural networks, it remains challenging to effectively model the long-tail class distribution in visual recognition tasks. For large-scale vision recognition tasks, partially due to the non-uniform distribution of natural object classes and varying annotation costs, we typically learn from datasets with a long-tail class label distribution. In such scenarios, the number of training instances per class varies significantly, from as few as one example for tail classes to hundreds or thousands for head classes. The intrinsic long-tail property of our visual data introduces a multitude of challenges for recognition in the wild, as a deep network model has to simultaneously cope with imbalanced annotations among the head and medium- sized classes, and few-shot learning in the tail classes.
To address this prob- lem, we first investigate the performance bottleneck ofthe two-stage learning framework via ablative study. Motivated by our discovery, we propose a unified distribution alignment strategy for long-tail visual recognition. Specifically, we de- velop an adaptive calibration function that enables us to adjust the classification scores for each data point. We then introduce a generalized re-weight method in the two-stage learning to balance the class prior, which provides a flexible and unified solution to diverse scenarios in visual recogni- tion tasks. We validate our method by extensive experiments on four tasks, including image classification, semantic seg- mentation, object detection, and instance segmentation. Our approach achieves the state-of-the-art results across all four recognition tasks with a simple and unified framework
The first author of this work is SIST PhD student Songyang Zhang, and Dr. Xuming He is the corresponding author. This work is also collaborated with Dr. Jian Sun and Zeming Li of Megvii Research. This research work was supported by Shanghai NSF Grant, ShanghaiTech start-up funding, National Key R&D Program of China and Beijing Academy of Artificial Intelligence (BAAI).
Songyang Zhang, Zeming Li, Shipeng Yan, Xuming He and Jian Sun, Distribution Alignment: A Unified Framework for Long-tail Visual Recognition
[LINK]
Read more at: https://arxiv.org/pdf/2103.16370
[GRAPHS AND NOTES]
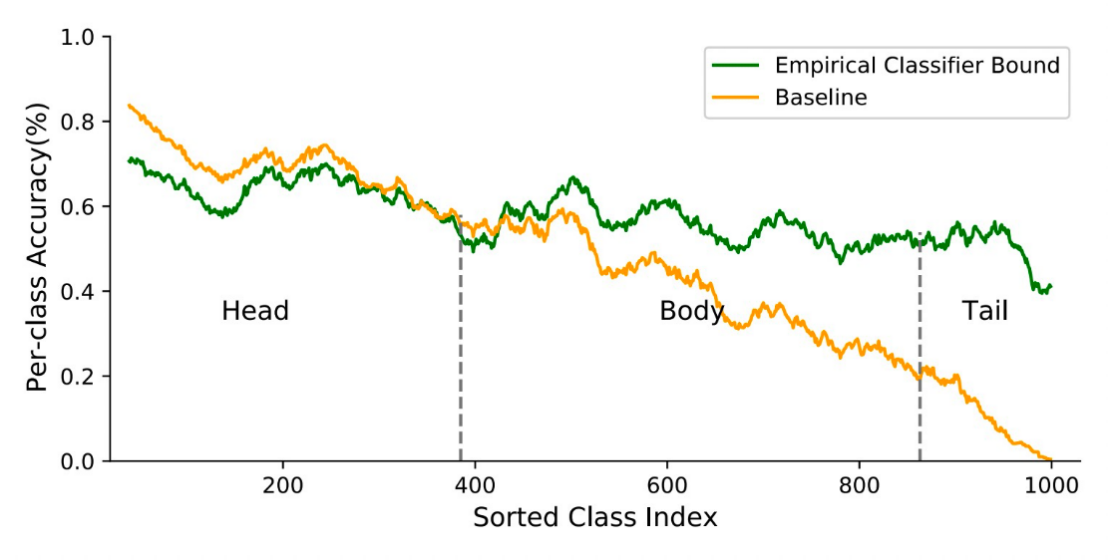
Fig.1 Per-class performance of the two-stage learning baseline and our empirical classification bound on ImageNet-LT val split.