2018年12月2日中午,我和另一位论文第一作者——中科院上海生命科学研究所李杰夫乘坐中国东方航空班机前往西班牙马德里,当地时间晚上7点30分左右到达。第二天上午我和李杰夫一起去举办会议的NH Collection酒店注册(图1为注册地点)。

图1 会议注册地点
下午workshop讲生物相关的,所以没太听懂;有些场是讲machine learning和生物的结合,比如“Evaluation of using a collective approach when selecting biomarker features from machine learning models.”,这篇讲了比较了5种机器学习模型,用于提取biomarker features,包括SVM、RF、PLS-DA、EN、KNN(见下图)。

图2
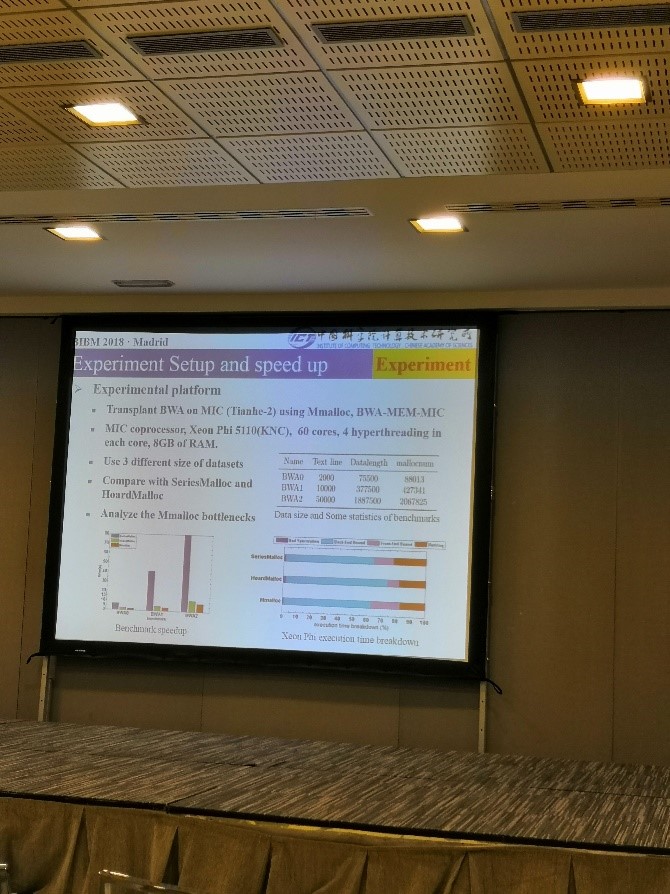
因为我们做的就是加速这方面的工作,所以后面两天听了一些关于“Acceleration, optimization, scalability and computability”的汇报,一篇关于使用卷积神经网络加速核磁共振成像——“Accelerated Super-resolution MR Image Reconstruction via a 3D Densely Connected Deep Convolutional Neural Network”,他们用的框架是caffe,问答环节有人问做汇报的人为什么不用PyTorch和TenforFlow之类的框架,他说caffe简单,框架这方面的使用真是见仁见智;一篇是分布式处理中间件VGE(Virtual Grid Engine),可用在超级计算机上,为了获得更大的加速,一些生物信息学的软件,比如测序工具,可以利用他们的中间件VGE在超级计算机上运行,代码是用Python写得,这个是来自东京大学的团队做的。然后还有一篇跟我们做的类似,用GPU加速细胞分析工具,获得了5-10倍左右的加速;最后是一篇关于改进MIC体系结构下的动态内存分配算法,用来加速存储密集型的生物应用程序,他们使用二分排序区间树来管理内存,作者比较了现有的两种分配器,PPT上展示了结果,获得了一定的提高(见图5)。期间还和一个来自四川大学的同学聊了几句,她做的是相似疾病检测上的跨疾病信息网络的表征学习。
除了这些,我们这几天也在修改用来汇报的PPT,查缺补漏,听听老师和其他合作者的意见,控制好演讲的时间。
|
图3
我们是最后一天(6号)上午做汇报(见图6),因为这篇论文主要是生物学上的东西,所以由另一位第一作者李杰夫做汇报,题目为“Paean: Parallel transcriptome quantification combing gene expression and alternative splicing event using GPU”。我们从以下几方面阐述论文:生物学背景介绍(转录组定量工具、RNA-Seq、瓶颈、GPU为什么能加速),结果(和目前的定量工具MISO的对比,时间上有一个极大的减少),设计和方法(统一地址范围和二分搜索)。

图4
讲的过程中我们着重把生物学意义和关键算法讲清楚,比如我们巧妙地把字符串的比较变为整数的范围对比,还有二分搜索,然后还有设计上的一些思路。李杰夫讲了10来分钟,听的人大概就10来个人,然后此次行程基本上就结束了。几天下来,给我的感觉是中国人非常多,有重庆大学的、哈尔滨工业大学的、四川大学的。身处异国,和国人说说话也是一种温暖。
在西班牙的晚上,我们经常徒步游览马德里,马德里的人喜欢晚上出来,人多,晚上很漂亮。欧式建筑在灯光的映衬下显得格外漂亮。

图5
收获和意义
总的来说,第一次出国,有苦有甜,语言不同,不知道怎么买地铁票,有时候坐错站,吃得也不习惯,但是学到了很多生活技能,还有在会议上认识了很多人,学到了专业知识,这将是我以后宝贵的财富!